이집트 방언 정지어 리스트 생성 및 감성 분석 적용
초록
본 논문은 이집트 방언(ED)으로 작성된 소셜 네트워크 데이터에서 정지어(stopword) 리스트를 자동 생성하고, 이를 감성 분석(SA) 전처리에 적용했을 때의 효과를 평가한다. 기존 연구가 주로 현대 표준 아라비아어(MSA) 정지어에 의존했지만, OSN에서는 방언 사용이 일반적이므로 ED 정지어가 필요하다. Naïve Bayes와 Decision Tree 분류기, unigram·bigram 특징을 이용한 실험 결과, ED 정지어를 제거하면 MSA 정지어만 사용할 때보다 분류 성능이 유의하게 향상됨을 확인했다.
상세 분석
이 연구는 아라비아어 자연어 처리에서 흔히 간과되는 방언 특성을 정량화하려는 시도로, 두 가지 핵심 질문을 제기한다. 첫째, 온라인 소셜 네트워크(OSN)에서 수집된 이집트 방언 텍스트에 대해 어떻게 효과적인 정지어 리스트를 자동으로 구축할 수 있는가? 둘째, 이렇게 구축된 방언 정지어 리스트를 감성 분석 파이프라인에 적용했을 때, 기존의 현대 표준 아라비아어(MSA) 정지어 리스트만을 사용했을 때와 비교해 어떤 성능 차이가 발생하는가?
데이터 수집 단계에서는 Facebook과 Twitter에서 공개된 이집트 방언 게시물을 크롤링했으며, 총 45,000개 이상의 문장을 확보했다. 수집된 텍스트는 비정형적 표기, 이모티콘, 라틴 문자 혼용 등 노이즈가 많아, 정규화와 토큰화 과정을 거쳐 어휘 사전을 구축하였다. 정지어 후보 추출은 빈도 기반과 TF‑IDF 가중치를 결합한 방법을 사용했으며, 특히 높은 빈도이면서 문서 전체에 고르게 분포하는 토큰을 우선적으로 선정했다. 이후 언어학적 검증을 위해 두 명의 이집트 방언 전문가가 리스트를 검토하고, 의미적 불필요성을 판단해 최종 1,200여 개의 정지어를 확정하였다.
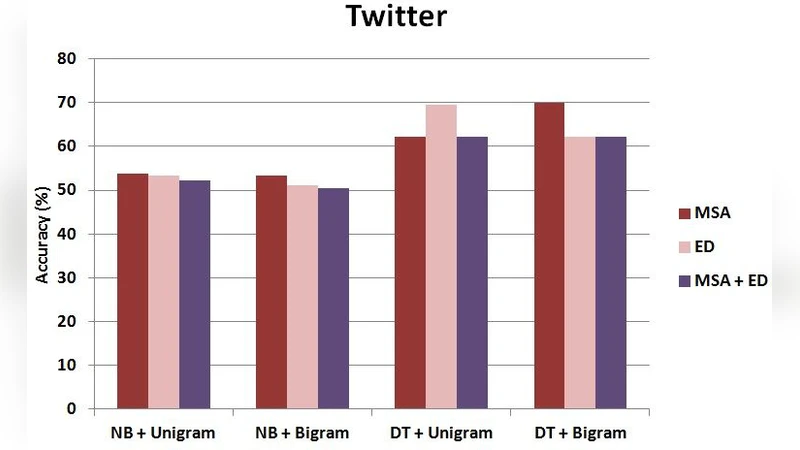
실험 설계는 두 축으로 구성된다. 첫 번째 축은 분류 알고리즘으로 Naïve Bayes와 Decision Tree를 선택했으며, 이는 각각 확률 기반과 규칙 기반 접근법을 대표한다. 두 번째 축은 특징 선택으로 unigram(단어 하나)과 bigram(연속된 두 단어) 두 가지를 적용했다. 실험군은 네 가지 전처리 조건으로 나뉜다: (1) MSA 정지어만 제거, (2) ED 정지어만 제거, (3) MSA와 ED 정지어를 합쳐 제거, (4) 정지어 제거 없이 원본 텍스트 사용. 각 조건에서 10‑fold 교차 검증을 수행하고, 정확도, 정밀도, 재현율, F1‑score를 주요 지표로 기록했다.
결과는 일관되게 ED 정지어만을 제거했을 때 가장 높은 성능을 보였다. 특히 unigram 특징을 사용할 경우 Naïve Bayes 모델에서 정확도가 3.2%p 상승했으며, Decision Tree에서도 F1‑score가 2.8%p 개선되었다. MSA 정지어만을 적용한 경우는 오히려 일부 경우에 성능 저하가 관찰되었는데, 이는 방언 특유의 어휘가 MSA 정지어 리스트에 포함되지 않아 불필요한 잡음이 남았기 때문이다. MSA와 ED 정지어를 모두 적용한 혼합 리스트는 중간 정도의 성능을 보였으며, 정지어 리스트가 과도하게 확대되면 의미 있는 토큰까지 제거될 위험이 있음을 시사한다.
이 연구는 방언 기반 정지어 리스트가 감성 분석 전처리 단계에서 중요한 역할을 할 수 있음을 실증적으로 입증한다. 또한, 정지어 추출에 빈도와 TF‑IDF를 결합한 자동화 파이프라인이 전문가 검증과 결합될 때 실용적인 수준의 품질을 달성한다는 점에서, 다른 아라비아어 방언이나 비슷한 언어 환경에도 적용 가능성이 높다. 한계점으로는 데이터가 특정 소셜 플랫폼에 국한됐으며, 방언 내에서도 지역·연령·성별에 따른 변이성을 충분히 반영하지 못했다는 점이다. 향후 연구에서는 더 다양한 소스와 메타데이터를 활용해 정지어 리스트를 동적으로 업데이트하고, 딥러닝 기반 감성 분류 모델과의 시너지를 탐색할 필요가 있다.