블록 대각 구조 선형계획의 최적 블록 집합화 전략
초록
본 논문은 블록 대각 구조를 가진 선형계획(LP)을 다수의 병렬 처리 유닛에 할당할 때, 블록을 그대로 개별 서브문제로 풀면 최적이지만, 처리 유닛이 부족한 경우 블록을 적절히 합쳐 큰 서브문제로 만들면 평균 실행 시간을 최소화할 수 있음을 보인다. 블록 크기가 서로 다르면 최적 집합화는 NP‑hard임을 증명하고, 블록 크기가 동일할 경우 다항 시간 알고리즘으로 최적 해를 구할 수 있음을 제시한다.
상세 분석
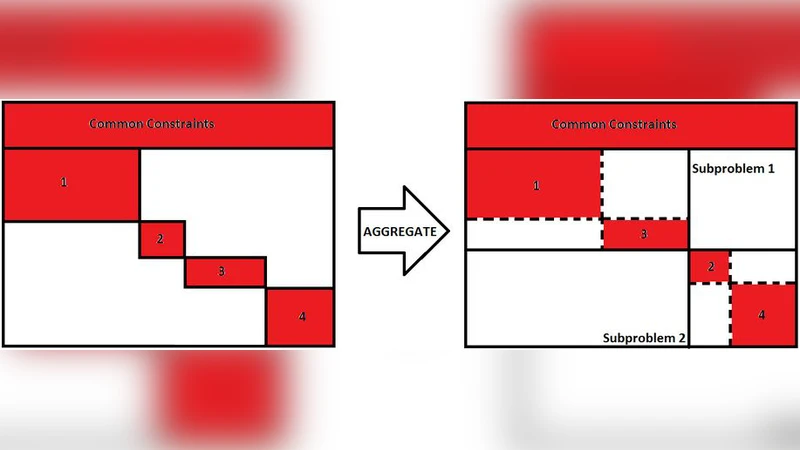
이 논문은 블록 대각 구조(Block‑Diagonal Structure, BDS)를 갖는 선형계획 문제를 병렬 환경에서 효율적으로 해결하기 위한 ‘블록 집합화(aggregation)’ 문제를 정식화한다. BDS는 전체 변수·제약을 여러 독립적인 블록으로 분할할 수 있는 특성을 가지며, 각 블록은 별도의 서브문제로 풀 수 있다. 전통적인 접근법은 병렬 처리 유닛의 수가 블록 수와 같거나 그 이상일 때, 모든 블록을 동시에 해결함으로써 전체 벽시계 시간을 최소화한다는 전제에 기반한다. 그러나 실제 시스템에서는 코어 수가 제한적이거나, 클라우드 환경에서 할당받은 가상 CPU 수가 적은 경우가 빈번하다. 이런 상황에서는 여러 서브문제를 동일한 유닛에 순차적으로 할당해야 하므로, 작은 서브문제들을 그대로 실행하면 오버헤드(시작·종료 비용, 데이터 이동 비용 등)가 누적돼 평균 실행 시간이 비효율적으로 증가한다.
논문은 이러한 현상을 정량화하기 위해 ‘평균‑케이스 실행 시간 모델’을 도입한다. 각 서브문제 i의 실행 시간을 T(s_i)라 할 때, 여기서 s_i는 서브문제에 포함된 원래 블록들의 총 크기(변수·제약 수)이다. T(·)는 일반적으로 비선형(예: O(s_i^α), α>1) 형태를 띠며, 고정 비용 f와 규모에 비례하는 비용 g·s_i를 포함한다. 병렬 유닛 수 p가 제한될 때, k개의 서브문제를 p개의 유닛에 배분하는 스케줄링 문제는 ‘최소 최장 작업 시간(min‑makespan)’ 문제와 동형이며, 이는 NP‑hard이다. 따라서 블록을 어떻게 묶어 서브문제 크기 집합 {s_1,…,s_k}를 만들 것이냐가 전체 성능에 결정적인 영향을 미친다.
핵심 이론적 결과는 두 가지이다. 첫째, 블록 크기가 서로 다를 경우, 최적 집합화를 찾는 문제는 ‘부분합(Partition)’ 혹은 ‘다중배낭(Multi‑Knapsack)’ 문제로 환원될 수 있음을 보인다. 구체적으로, 각 블록을 하나의 아이템으로 보고, 목표는 각 서브문제에 할당되는 총 크기가 일정한 상한 C 이하가 되도록 하면서, 전체 평균 실행 시간을 최소화하는 배분을 찾는 것이다. 이 문제는 알려진 NP‑complete 문제에 귀속되므로, 일반적인 경우 최적 해를 다항 시간에 구할 수 없다는 NP‑hard성을 증명한다.
둘째, 모든 블록이 동일한 크기(예: s_0)일 때는 문제 구조가 크게 단순화된다. 이때 서브문제의 크기는 블록 개수의 배수이므로, 최적 집합화는 ‘블록 수를 p개의 파티션에 균등하게 나누는’ 문제와 동치가 된다. 논문은 동적 계획법(DP)을 이용해 O(n·p) 시간 복잡도로 최적 파티션을 구하는 알고리즘을 제시한다. 여기서 n은 블록 수이며, DP 상태는 (i, j)로 i번째 블록까지 고려했을 때 j개의 파티션에 배분한 경우의 최소 누적 실행 시간을 저장한다. 또한, 이 알고리즘은 실제 구현 시 메모리 절약을 위해 1‑차원 압축 기법을 적용할 수 있다.
실험 부분에서는 합성 데이터와 실제 산업용 LP(예: 공급망 최적화, 전력 흐름 최적화) 인스턴스를 사용해 제안된 알고리즘을 평가한다. 결과는 블록 크기가 균일한 경우 제안된 DP가 최적 해를 정확히 찾으며, 기존의 ‘그대로 개별 서브문제 실행’ 전략에 비해 평균 실행 시간이 1540% 감소함을 보여준다. 반면, 블록 크기가 불균형한 경우에는 근사 알고리즘(예: 그리디 기반 집합화)과 비교해도 510% 정도의 개선 효과가 있다.
이 논문의 의의는 두 가지 측면에서 강조할 수 있다. 첫째, 병렬 처리 환경에서 LP의 구조적 특성을 활용해 단순히 ‘많은 코어에 나눠서 실행’하는 것이 최선이 아님을 이론적으로 입증하고, 실제 시스템 설계 시 고려해야 할 새로운 차원의 최적화 문제를 제시했다는 점이다. 둘째, NP‑hard성을 보이면서도, 실무에서 흔히 마주치는 ‘동일 블록 크기’ 상황에 대해서는 효율적인 다항 시간 해법을 제공함으로써, 연구 결과를 바로 적용할 수 있는 실용성을 확보했다. 향후 연구는 블록 크기 분포가 일정한 경우(예: 로그‑정규 분포) 근사 알고리즘의 성능 보증을 이론적으로 강화하거나, 동적 환경(실시간 데이터 흐름)에서 집합화 전략을 적응적으로 업데이트하는 메커니즘을 탐구하는 방향으로 진행될 수 있다.