클래스 벡터 문서 클래스 임베딩 표현
초록
본 논문은 단어와 문단 임베딩과 동일한 공간에 각 클래스의 벡터를 학습하는 “클래스 벡터” 방식을 제안한다. 클래스 벡터와 단어 벡터 간 코사인 유사도를 특징으로 활용해 감성 분석 데이터셋(Yelp, Amazon 전자제품)에서 기존 방법과 동등하거나 우수한 성능을 보이며, 클래스별 의미를 직관적으로 파악할 수 있다.
상세 분석
본 연구는 기존의 워드 임베딩(skip‑gram, GloVe 등)과 문단 임베딩(Paragraph Vector)에서 영감을 받아, 클래스 자체를 하나의 “단어”처럼 취급하고 해당 클래스 ID와 모든 학습 문서의 단어가 동시에 co‑occurrence하도록 설계하였다. 이를 위해 원본 skip‑gram 목표함수에 클래스‑단어 쌍의 로그우도 항을 λ 가중치와 함께 추가함으로써, 클래스 벡터와 단어 벡터가 동일한 매개변수 공간에서 공동 학습된다.
학습 단계에서는 각 클래스 ID가 해당 클래스에 속한 모든 문장의 윈도우에 포함되므로, 클래스 벡터는 해당 클래스의 전형적인 어휘와 높은 코사인 유사도를 갖게 된다. 논문은 세 가지 예측 방식을 제시한다. 첫째, 문서 내 모든 단어에 대해 클래스‑단어 소프트맥스 확률을 로그합산해 가장 큰 점수를 가진 클래스를 선택하는 “CV Score” 방식; 둘째, 각 단어에 대해 양·음성 클래스 확률 로그 차이를 특징으로 사용해 로지스틱 회귀(LR)와 결합하는 “CV‑LR” 방식; 셋째, 정규화된 벡터 간 내적 차이를 직접 특징으로 활용하는 “norm CV‑LR” 방식이다.
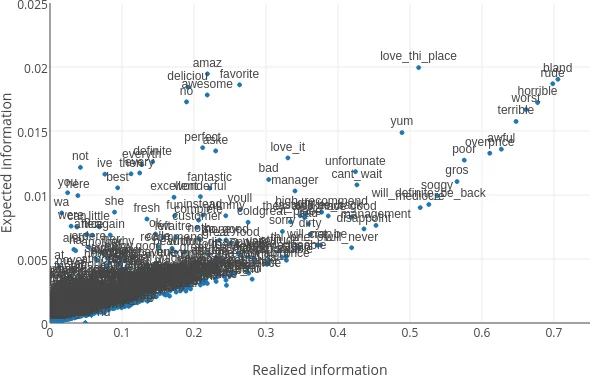
특징 선택 측면에서는 클래스 벡터와 단어 벡터 간 내적을 확률 p(c|w) 로 해석하고, 이를 기반으로 조건부 엔트로피와 상호정보량을 계산한다. 실험 결과, 저빈도 단어라도 높은 상호정보량을 가질 경우 클래스 벡터 기반 특징 선택이 전통적인 TF‑IDF 대비 우수함을 확인하였다.
데이터셋은 Amazon 전자제품 리뷰(≈196k 학습, 25k 테스트)와 Yelp 레스토랑 리뷰(≈154k 학습, 20k 테스트)로, 각각 2‑클래스(긍정/부정) 감성 분류 문제에 적용하였다. 전처리는 소문자 변환 및 구두점 제거이며, 빈도 5 이하 단어는 제외하였다. 또한, Kumar et al. (2014) 방식으로 중요한 구문을 추출해 문서에 태깅함으로써 모델 성능을 향상시켰다.
성능 비교에서는 기본 BOW(바이너리, TF, IDF, TF‑IDF), Naive Bayes‑LR, 사전 훈련된 워드2벡터 기반 변형(W2V inversion), CNN, Paragraph Vector(PV‑DBOW)와 제안된 클래스 벡터 기반 방법을 평가하였다. Yelp 데이터에서는 norm CV‑LR이 94.91% 정확도로 가장 높은 성능을 기록했으며, CV‑LR도 94.83%로 경쟁력을 보였다. Amazon 데이터에서는 BOW‑IDF가 93.98%로 최고였지만, CV‑LR이 91.70%로 비교적 높은 점수를 얻었다. 특히, 클래스 벡터가 “very very good”, “fantastic” 등 긍정 어휘와, “awful”, “terrible” 등 부정 어휘와 높은 유사도를 보이며, 클래스 의미를 직관적으로 해석할 수 있었다.
추가 실험에서 클래스 벡터 학습 시 전체 코퍼스를 섞어 사용하지 않으면 클래스 간 구분력이 크게 감소한다는 점을 발견했으며, 이는 클래스 ID가 모든 문서와 동시에 학습될 때 의미적 정렬이 이루어짐을 시사한다. 또한, 저빈도 단어가 높은 상호정보량을 가질 경우, 기존 TF‑IDF 기반 특징 선택보다 클래스 벡터 기반 선택이 더 효과적임을 시각화(Figure 2)로 제시하였다.
결론적으로, 클래스 벡터는 기존 임베딩 방법에 비해 추가적인 파라미터 비용이 거의 없으며, 클래스 의미를 명시적으로 표현하고, 간단한 로지스틱 회귀와 결합해 강건한 텍스트 분류 성능을 달성한다. 향후 연구 방향으로는 사전 훈련된 워드 임베딩을 활용한 클래스 벡터 초기화, n‑그램 조합을 통한 고차원 특징 확장, 그리고 클래스 벡터를 이용한 텍스트 클러스터링 및 생성 모델 개발이 제시된다.
댓글 및 학술 토론
Loading comments...
의견 남기기