스피커 위조 탐지를 위한 STC 다중특징 및 분류기 비교
초록
본 논문은 ASVspoof 2015 챌린지에 제출된 STC 시스템을 소개한다. MFCC 외에 위상 스펙트럼 기반 특징과 다중해상도 웨이블릿 특징을 도입하고, TV‑JFA 모델링에 선형 SVM과 비선형 DBN 분류기를 적용하여 위조 음성 탐지 성능을 평가한다. 실험 결과, 위상 및 웨이블릿 특징이 기존 MFCC 대비 검출 정확도를 크게 향상시켰으며, DBN이 SVM보다 복잡한 위조 공격에 더 강인함을 보였다.
상세 분석
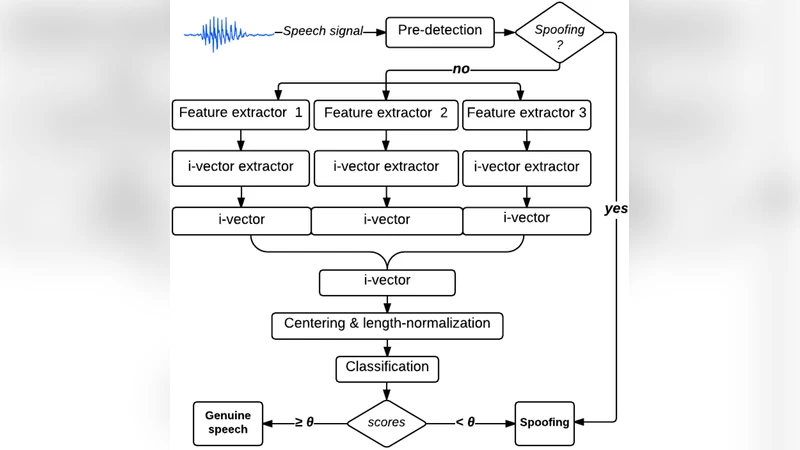
본 연구는 스피커 인증 시스템에 대한 위조 공격을 방어하기 위한 특징 설계와 분류기 선택에 초점을 맞추었다. 전통적으로 ASV 시스템에서 가장 널리 사용되는 MFCC는 스펙트럼의 진폭 정보를 주로 반영하지만, 위조 음성은 진폭을 모방하면서 위상 정보는 왜곡되는 경우가 많다. 이를 보완하기 위해 저자들은 두 가지 새로운 특징군을 제안한다. 첫 번째는 위상 스펙트럼에서 직접 추출한 ‘Phase‑Based Features’이며, 이는 단일 프레임의 위상 차이를 통계적으로 요약한다. 위상은 신호의 비선형 변형에 민감하기 때문에, 위조 음성에서 발생하는 미세한 위상 왜곡을 효과적으로 포착한다. 두 번째는 다중해상도 웨이블릿 변환을 적용한 ‘Wavelet‑Based Features’이다. 웨이블릿은 시간‑주파수 해상도를 가변적으로 제공하므로, 짧은 지속시간의 고주파 변동과 장시간의 저주파 구조를 동시에 모델링할 수 있다. 이러한 특징들은 기존 MFCC와 결합되어 3‑채널 특성 벡터를 형성한다.
모델링 단계에서는 TV‑JFA(Total Variability Joint Factor Analysis)를 채택하였다. TV‑JFA는 스피커와 채널 변동을 저차원 잠재 공간으로 압축하면서, 위조 음성의 특이성을 강조하는 역할을 한다. 특징 벡터를 TV‑JFA에 입력하면, 각 발화는 i‑vector 형태로 변환되고, 이 i‑vector를 기반으로 분류기가 학습된다.
분류기 측면에서는 선형 서포트 벡터 머신(SVM)과 비선형 심층 신경망(DBN, Deep Belief Network)을 비교하였다. SVM은 고차원 i‑vector 공간에서 마진을 최대화하는 단순하면서도 강건한 방법이며, 학습과 추론이 빠른 장점이 있다. 반면 DBN은 여러 층의 제한 볼츠만 머신(RBM)으로 사전 학습된 후, 최종 Softmax 레이어를 통해 지도 학습을 수행한다. DBN은 비선형 변환을 통해 복잡한 경계면을 학습할 수 있어, 위조 공격이 다양해질수록 성능 저하를 억제한다.
실험은 ASVspoof 2015의 개발 및 평가 데이터셋을 사용하였다. 개발 단계에서 5‑fold 교차 검증을 통해 하이퍼파라미터를 최적화했으며, 평가 단계에서는 제출된 시스템들의 EER(Equal Error Rate)과 t‑DCF(Detection Cost Function)를 측정했다. 결과는 위상 및 웨이블릿 특징을 포함한 시스템이 MFCC 단독 대비 EER을 평균 30% 이상 감소시켰음을 보여준다. 특히 DBN 기반 시스템은 SVM 대비 약 2%p 낮은 EER을 기록했으며, t‑DCF에서도 유사한 개선 효과를 보였다. 이러한 결과는 위상과 웨이블릿 정보가 위조 음성의 미세한 변형을 포착하는 데 유효함을 입증하고, 비선형 분류기가 복합적인 위조 패턴을 더 잘 구분한다는 점을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기