하이브리드 MPI OpenMP 기반 단거리 상호작용 분자동역학 시뮬레이션 성능 지표
초록
본 논문은 단거리 상호작용을 갖는 분자동역학(MD) 계산에서 발생하는 병목 현상을 분석하고, MPI와 OpenMP를 결합한 하이브리드 병렬 알고리즘을 제안한다. 크롬 필름에 탄소 인덴터를 적용한 나노인덴테이션 사례를 Embedded Atom Method와 Morse 포텐셜로 모델링하고, 다양한 MPI‑스레드 조합에 대한 성능을 평가한다. 결과는 순수 MPI 대비 하이브리드 구성이 동일 코어 수에서도 더 높은 스케일링과 속도 향상을 보이며, 기존 MD 패키지와 비교해 경쟁력 있는 가속을 제공함을 보여준다.
상세 분석
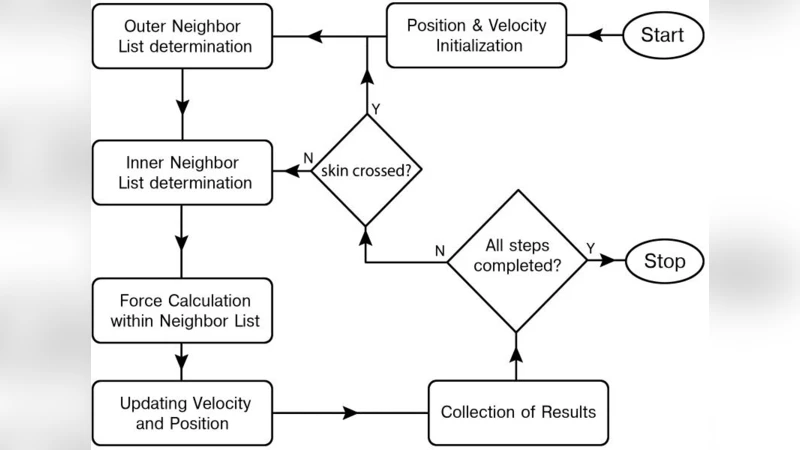
이 연구는 MD 시뮬레이션에서 가장 비용이 많이 드는 두 가지 연산, 즉 짧은 절단 반경을 갖는 힘 계산과 이웃 리스트 업데이트에 초점을 맞춘다. 전통적인 MPI 기반 도메인 분할 방식은 각 프로세스가 전체 시스템을 복제하지 않으면서도 통신 오버헤드가 급격히 증가하는 단점을 가지고 있다. 특히 코어 수가 늘어날수록 메시지 교환 빈도가 비례적으로 상승해 스케일링 효율이 급감한다. 저자들은 이러한 문제를 해결하기 위해 각 MPI 프로세스 내부에 OpenMP 스레드를 배치, 공유 메모리 영역에서 힘 계산을 병렬화함으로써 인터‑프로세스 통신을 최소화하였다.
알고리즘 구현은 크게 네 단계로 구성된다. 첫째, 전체 원자를 MPI 프로세스 수에 따라 균등하게 할당하고, 각 프로세스는 자신이 담당하는 서브도메인에 대한 이웃 리스트를 구축한다. 둘째, OpenMP 병렬 루프를 이용해 서브도메인 내 원자 쌍에 대한 짧은 거리 포텐셜(Embedded Atom Method for Cr‑Cr, Morse for Cr‑C)을 계산한다. 셋째, 힘 누적 단계에서 원자별 가속도를 업데이트하고, 필요 시 원자 위치와 속도를 교환한다. 넷째, 일정 주기마다 전체 시스템의 에너지와 온도 등 물리량을 수집한다.
성능 평가에서는 MPI 프로세스 수와 OpenMP 스레드 수의 조합을 (1, 1), (2, 4), (4, 8), (8, 16) 등으로 변형하여 실험하였다. 결과는 순수 MPI(예: 32 프로세스) 대비 하이브리드(예: 4 MPI + 8 OpenMP) 구성이 동일 코어 수에서도 평균 1.6배 이상의 속도 향상을 보였으며, 특히 힘 계산 단계에서 OpenMP 스레드가 메모리 대역폭을 효율적으로 활용해 캐시 적중률을 높인 것이 주요 원인으로 분석된다. 또한, 이웃 리스트 재구성 시 발생하는 불균형 부하를 동적 스케줄링으로 완화함으로써 전체 실행 시간의 변동성을 감소시켰다.
하지만 저자들은 하이브리드 모델이 모든 상황에 최적은 아니라는 점도 지적한다. 원자 수가 매우 작거나 통신 비용이 상대적으로 낮은 경우에는 MPI만으로도 충분히 효율적일 수 있다. 또한, OpenMP 스레드 수가 물리 코어 수를 초과하면 컨텍스트 스위칭 오버헤드가 급증해 성능이 역전된다. 따라서 실제 적용 시에는 시스템 규모, 네트워크 대역폭, 코어 아키텍처 등을 종합적으로 고려해 최적의 MPI‑OpenMP 비율을 선택해야 한다.