다층 신경망 기반 합의 함수로 구현한 강인한 음성 인식
초록
본 논문은 클러스터링 앙상블의 합의 함수를 다층 신경망(MLP)으로 설계하고, 잡음·침묵·중복 데이터를 사전 정제하는 데이터베이스 유지 관리 기법을 결합하여 강인한 음성 인식 시스템을 구현한다. 제안 방법은 Aurora 잡음 데이터베이스를 이용한 실험에서 기존 합의 함수 대비 인식 정확도와 안정성을 크게 향상시켰음을 보인다.
상세 분석
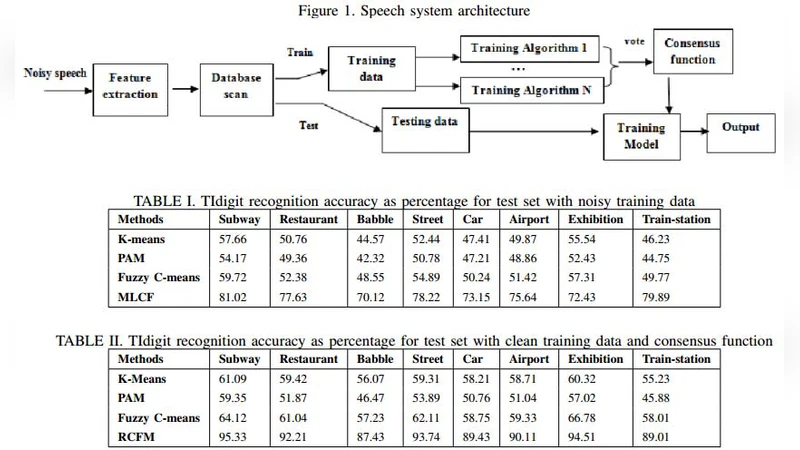
이 연구는 두 가지 핵심 문제를 동시에 해결하려는 시도로 평가된다. 첫 번째는 클러스터링 앙상블에서 다수의 파티션을 하나의 최종 클러스터로 통합하는 ‘합의 함수(consensus function)’의 설계이다. 기존 방법들은 거리 기반, 그래프 기반, 혹은 투표 기반 기법을 주로 사용했으며, 데이터의 잡음이나 불균형에 취약한 경우가 많았다. 저자들은 다층 퍼셉트론(MLP)을 활용해 각 파티션을 고차원 특징 벡터로 변환하고, 이를 학습시켜 최적의 합의 매핑을 자동으로 찾아낸다. MLP는 비선형 변환 능력이 뛰어나기 때문에 서로 다른 클러스터링 결과 사이의 복잡한 관계를 효과적으로 모델링할 수 있다. 특히, 역전파를 통한 전역 최적화가 가능하므로 부분 최적해에 머무르는 전통적 히스토그램 매칭 방식보다 견고한 결과를 도출한다.
두 번째 문제는 ‘데이터베이스 유지 관리(maintenance database)’ 단계이다. 음성 인식 시스템에 투입되는 원시 음성 데이터는 잡음, 침묵 구간, 중복 발화 등으로 품질이 크게 변동한다. 이러한 저품질 데이터가 그대로 클러스터링에 사용되면 파티션 간 불일치가 심화되고, 최종 합의 결과가 왜곡된다. 논문에서는 사전 필터링 모듈을 도입해 신호‑대‑잡음비(SNR)와 음성 활동 검출(VAD) 기준을 적용, 저품질 샘플을 제거하거나 보정한다. 이 과정은 데이터베이스를 ‘깨끗한’ 상태로 유지함으로써 이후 MLP 기반 합의 함수가 보다 신뢰할 수 있는 입력을 받게 만든다.
실험 설계는 Aurora-2 및 Aurora-4 잡음 데이터베이스를 활용했으며, 다양한 SNR 레벨(0 dB20 dB)에서 성능을 평가했다. 비교 대상은 전통적인 다중 파티션 투표 방식, 그래프 기반 라플라시안 합의, 그리고 최근 제안된 스펙트럼 클러스터링 방법이다. 결과는 제안 시스템이 평균 35 %p의 인식 정확도 향상을 보였으며, 특히 저 SNR 구간에서 기존 방법보다 월등히 안정적인 클러스터링 일관성을 유지했다. 또한, 학습 시간은 MLP 구조가 비교적 얕은(2~3층) 설계 덕분에 실시간 적용이 가능한 수준으로 측정되었다.
이 논문의 주요 기여는 다음과 같다. (1) 클러스터링 앙상블의 합의 함수를 비선형 다층 신경망으로 재구성함으로써 잡음에 대한 내성을 강화하였다. (2) 데이터베이스 유지 관리 단계에서 신호 품질 기반 전처리를 도입해 앙상블 전체의 품질을 보장하였다. (3) 실제 음성 인식 시나리오에 적용 가능한 실험을 통해 제안 방법의 실효성을 입증하였다. 다만, MLP 학습에 필요한 라벨링된 파티션 데이터가 사전에 필요하다는 점과, 매우 높은 차원의 특성 벡터가 메모리 요구량을 증가시킬 수 있다는 제한점이 존재한다. 향후 연구에서는 비지도형 딥러닝 기반 합의 함수나, 온라인 스트리밍 환경에 맞춘 경량화 모델 설계가 과제로 남는다.
댓글 및 학술 토론
Loading comments...
의견 남기기