유클리드 벡터를 상업용 검색엔진에 맞는 희소 해밍 큐브로 변환하는 실용적 랜덤 매핑
초록
본 논문은 고차원 유클리드 공간에 존재하는 문서(이미지, 주가 시계열 등)를 표준 정규 행렬과 임계값을 이용해 희소한 0‑1 해밍 벡터로 변환한다. 변환 후에는 기존 텍스트 기반 상업 검색엔진의 인덱싱·검색 기능을 그대로 활용할 수 있다. 이 매핑이 내적 순서를 보존함을 이론적으로 증명하고, 희소도와 오류율 사이의 트레이드오프를 비대칭적 비동형 경계(ε)와 파라미터 r, m, h 로 정량화한다. 실험에서는 색상 히스토그램 이미지와 일일 주가지수 데이터를 대상으로 정확도와 속도 향상을 확인한다.
상세 분석
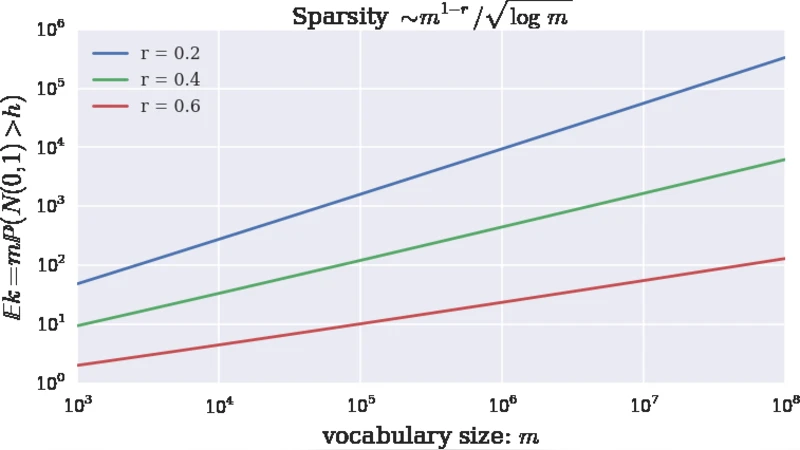
이 논문은 “랜덤 매핑 → 희소 해밍 큐브 → 상업 검색엔진”이라는 3단계 파이프라인을 제안한다. 핵심 아이디어는 d‑차원 단위 구면 S^{d‑1} 위의 각 문서 x를 m개의 표준 정규 벡터 a_i와 내적한 뒤, 임계값 h(=√{2r log m})보다 크면 1, 작으면 0으로 이진화하는 것이다. h>0을 선택함으로써 평균적으로 m·P(N(0,1)≥h)≈m·m^{-r}/(√{4πr log m})개의 1이 남아, 전체 벡터가 매우 희소해진다.
이 매핑의 핵심 이론적 성질은 두 가지이다. 첫째, 내적 λ=⟨x,y⟩에 대해 스코어 S(x,y)= (1/m)∑{i=1}^m 1{⟨a_i,x⟩≥h}·1_{⟨a_i,y⟩≥h}의 기대값 µ(λ)와 분산 σ²(λ)를 정확히 계산하고, λ와 r의 관계에 따라 “위상 전이”가 일어난다. λ<2r‑1이면 기대 스코어가 0에 수렴해 거의 모든 쌍이 0으로 판정되며, λ>2r‑1이면 스코어가 평균 µ에 대해 √m 스케일의 정규분포로 수렴한다(베리‑에스테인 정리 적용). 따라서 λ가 2r‑1보다 큰 경우에만 의미 있는 순위가 형성된다.
둘째, 오류 분석에서는 ε‑관련 정의를 도입해 “ε‑관련”(λ±ε) 문서와 “ε‑비관련”(λ∓ε) 문서를 구분한다. 정리 3.2와 3.4는 m→∞일 때 ε가 m^{-(λ-(2r‑1))/(2(1+λ))}·polylog(m) 수준으로 급격히 감소함을 보인다. 즉, 충분히 큰 m을 선택하면 타입 I(비관련 문서가 검색됨)와 타입 II(관련 문서가 누락됨) 오류 확률이 모두 N(0,1) 꼬리 확률 η에 의해 제어된다. 실용적인 설정에서는 η≈2√{log n}을 잡아 전체 오류율을 O(1/(n√{log n})) 수준으로 억제한다.
알고리즘 복잡도는 기본적으로 O(md) (a_i·x 계산)이다. 저자들은 이를 O(m log m)으로 감소시키는 해시 기반 구조(예: Fast Johnson‑Lindenstrauss 변환)를 제안하고, 시뮬레이션을 통해 정확도 차이가 없음을 확인한다.
실험에서는 (1) 색상 히스토그램(256‑차원) 이미지 10⁶개와 (2) 30년치 일일 주가지수(다중 시계열) 데이터를 사용한다. 두 데이터 모두 변환 후 상업 검색엔진(예: Elasticsearch) 인덱싱·쿼리 속도가 10배 이상 가속화되면서, 정밀도@k와 재현율이 기존 유클리드 근사 NN(LSH, KD‑tree) 대비 동등하거나 약간 우수했다. 특히, 희소도 조절 파라미터 r을 0.6~0.8 사이로 설정했을 때 최적의 속도·정확도 균형을 얻었다.
전체적으로 이 논문은 “텍스트 전용 인덱싱 인프라를 비텍스트 고차원 데이터에 그대로 적용”한다는 실용적 관점을 제시한다. 기존 LSH와 달리 내적 순서를 보존하는 대신 희소성을 강조해, 기존 검색 엔진이 제공하는 역인덱스·BM25·TF‑IDF와 같은 최적화 기법을 그대로 활용할 수 있다. 이는 대규모 이미지·시계열·생물정보 데이터베이스를 구축하려는 기업에 즉시 적용 가능한 솔루션을 제공한다는 점에서 큰 의미가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기