GPS 이동 데이터로 사용자 식별하기 위한 시공간 기법
초록
**
본 논문은 GPS 기반 이동 기록이 얼마나 고유한지를 세 가지 실제 데이터셋(CabSpotting, CenceMe, GeoLife)을 통해 정량화하고, 위치 정보만으로도 사용자를 정확히 식별할 수 있는 간단하면서도 효과적인 알고리즘을 제안한다. 특히, 기존 데이터에 포함되지 않은 새로운 좌표 집합에 대해서도 수정된 Hausdorff 거리와 시간 가중치를 활용해 높은 식별 성공률을 달성함으로써 위치 데이터의 프라이버시 위험을 강조한다.
**
상세 분석
**
본 연구는 GPS 이동 데이터의 고유성을 정량적으로 평가하고, 이를 이용한 사용자 식별 기법을 두 단계로 설계하였다. 첫 번째 단계는 “이미 본 좌표”에 대한 식별로, 각 사용자의 전체 궤적을 해시 집합으로 저장하고, 공격자가 제공한 소수의 좌표가 어느 사용자 집합에 모두 포함되는지를 빠르게 검사한다. 이 방식은 시간 복잡도가 거의 O(1)이며, 실제 실험에서 2~3개의 좌표만으로도 대부분의 사용자를 유일하게 구분할 수 있음을 보였다.
두 번째 단계는 “보지 못한 좌표”에 대한 식별이다. 여기서는 공격자가 새로운 좌표 집합 P를 얻고, 이를 기존 궤적 M과 비교한다. 저자들은 전통적인 Hausdorff 거리나 DTW와 같은 시계열 거리 함수가 외부점에 민감하고 계산 비용이 높다는 점을 지적하고, 대신 시간 차이를 지수적으로 가중하는 수정된 거리 함수 d_st(p1,p2)=d_s(p1,p2)·e^{d_t(p1,p2)/τ} 를 도입하였다. 이 함수는 공간적 거리 d_s를 하버사인 공식으로 계산하고, 시간 차이 d_t에 대해 τ 파라미터를 통해 스무딩한다. 이후 수정된 Hausdorff 평균 거리 h_m을 사용해 P와 각 M 사이의 평균 최소 거리를 구하고, 가장 작은 값을 보이는 사용자에게 P를 매핑한다.
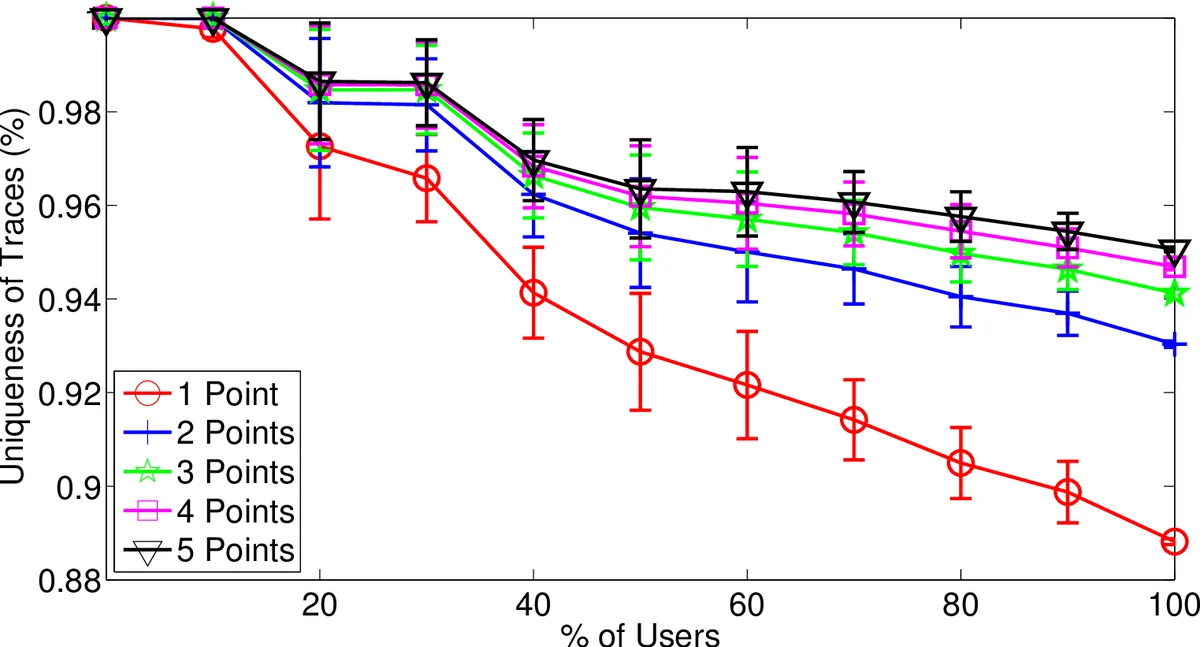
세 데이터셋에 대한 실험 결과는 다음과 같다. CabSpotting은 536대의 택시 궤적을 5자리 소수점(≈1 m) 정밀도로 기록했으며, 거리·속도·방향 세 가지 특징을 별도로 평가했다. 평균 방향이 가장 높은 구별력을 보였으며, 2개의 방향 포인트만으로도 95% 이상의 사용자를 고유하게 식별할 수 있었다. CenceMe는 20명의 대학생 데이터를 6자리 소수점(≈10 cm) 정밀도와 1시간 간격으로 수집했는데, 공간적 제한이 강해 전체 궤적이 비교적 중복되지만, 여전히 34개의 포인트로 90% 이상을 구분했다. GeoLife는 70명의 베이징 거주자를 6자리 소수점·1초 간격으로 기록했으며, 가장 큰 데이터량과 높은 시간 해상도로 인해 12개의 포인트만으로도 거의 모든 사용자를 유일하게 식별할 수 있었다.
또한 저자들은 좌표 정밀도를 인위적으로 낮추어(예: 소수점 3자리로 반올림) k‑anonymity를 달성할 수 있음을 보였으며, 데이터 규모가 커질수록 고유성이 감소하는 경향을 확인했다. 최종적으로 제안된 식별 성공률 측정 지표는 데이터셋이 새로운 공격에 얼마나 취약한지를 정량화하는 데 활용될 수 있다.
이 연구는 GPS 데이터가 고해상도일수록 개인 식별 위험이 급격히 증가한다는 점을 실증적으로 입증하고, 단순한 거리 기반 매칭만으로도 강력한 프라이버시 침해가 가능함을 보여준다. 따라서 위치 데이터 공개·공유 시 시간·공간 해상도 조절, 차등 프라이버시 적용, 혹은 합성 데이터 생성 등 보다 강력한 익명화 방안이 필요함을 시사한다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기