웹 세션 클러스터링 성능과 타당성 정량 평가
초록
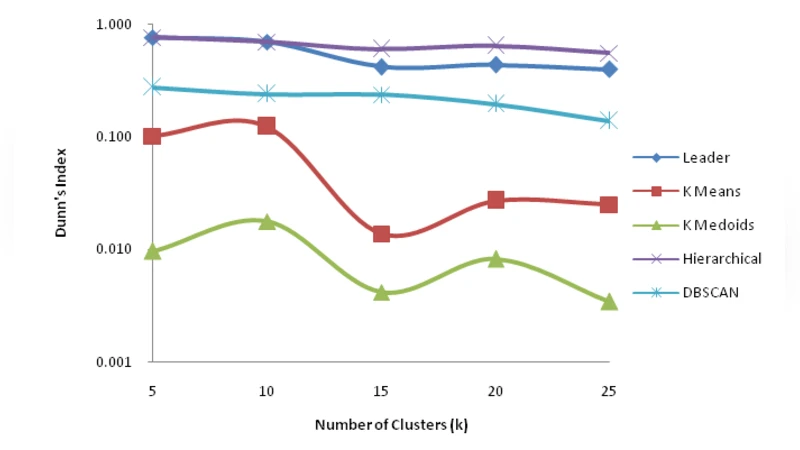
본 연구는 웹 로그에서 추출한 사용자 탐색 세션을 대상으로 k‑Means, k‑Medoids, Leader, 단일 연결 계층적 군집화, DBSCAN 등 다섯 가지 클러스터링 알고리즘을 적용하고, Dunn, Davies‑Bouldin, C, Silhouette, Rand, Jaccard, Fowlkes‑Mallows, SSE 등 8개의 내부·외부 타당성 지표를 이용해 성능을 정량적으로 비교한다. 실험 결과 각 알고리즘은 정확도와 계산 비용 측면에서 서로 다른 장단점을 보이며, 목적에 맞는 알고리즘 선택을 위한 가이드라인을 제시한다.
상세 분석
본 논문은 웹 사용 로그를 기반으로 사용자 탐색 세션을 추출한 뒤, 다양한 클러스터링 알고리즘의 성능과 군집 타당성을 정량적으로 평가한다. 먼저 로그 전처리 단계에서 사용자 식별, 세션 구분, URL 정규화 등을 수행하여 세션 벡터를 구성한다. 이때 세션은 페이지 방문 횟수 혹은 방문 순서를 특징으로 하는 고차원 희소 벡터로 변환된다. 이후 k‑Means, k‑Medoids, Leader, 단일 연결 계층적 군집화, DBSCAN 등 다섯 가지 대표적인 군집화 기법을 동일한 데이터셋에 적용한다. 각 알고리즘은 파라미터 튜닝 과정을 거쳐 최적의 군집 수 혹은 밀도 기준을 결정한다. 군집 결과의 품질 평가는 내부 타당성 지표(Dunn Index, Davies‑Bouldin Index, C Index, Silhouette)와 외부 타당성 지표(Rand Index, Jaccard Index, Fowlkes‑Mallows)를 동시에 사용한다. 또한 군집 중심과 데이터 간 거리의 합인 SSE를 계산하여 알고리즘의 수렴 속도와 계산 비용을 비교한다. 실험 결과, k‑Means와 k‑Medoids는 높은 실루엣 점수와 낮은 SSE를 보이며 군집 내부 응집도가 우수했지만, 군집 수가 증가함에 따라 Rand Index가 감소하는 경향을 나타냈다. 반면 DBSCAN은 노이즈 포인트를 효과적으로 분리하고 Jaccard Index가 가장 높았으나, 파라미터 ε와 MinPts에 민감해 결과가 불안정했다. Leader 알고리즘은 실행 시간이 가장 짧았지만, Dunn Index와 Davies‑Bouldin Index가 낮아 군집 간 분리가 약했다. 단일 연결 계층적 군집화는 전체적인 군집 구조를 시각화하는 데 유리했지만, 대규모 데이터에서는 계산 복잡도가 급증했다. 논문은 이러한 정량적 지표들을 종합해 각 알고리즘의 강점과 약점을 명확히 제시하고, 웹 세션 분석에서 목적에 맞는 군집화 기법 선택 가이드를 제공한다. 또한, 다중 타당성 지표를 동시에 활용함으로써 단일 지표에 의존하는 평가의 한계를 극복하고, 실무 적용 시 신뢰성 있는 의사결정을 지원한다.