자동으로 랜덤 워크를 클러스터링하는 비모수 방법
본 논문은 마코프 과정, 특히 금융 시계열의 랜덤 워크를 비모수적으로 표현하고, 의존성 및 주변분포를 분리한 뒤 하나의 파라미터 θ로 조절되는 거리함수를 정의하여 자동 군집화를 수행한다. 실험은 CDS 거래량 데이터를 이용해 θ 값에 따라 3~7개의 군집이 도출되는 과정을 보여준다.
저자: Gautier Marti, Frank Nielsen, Philippe Very
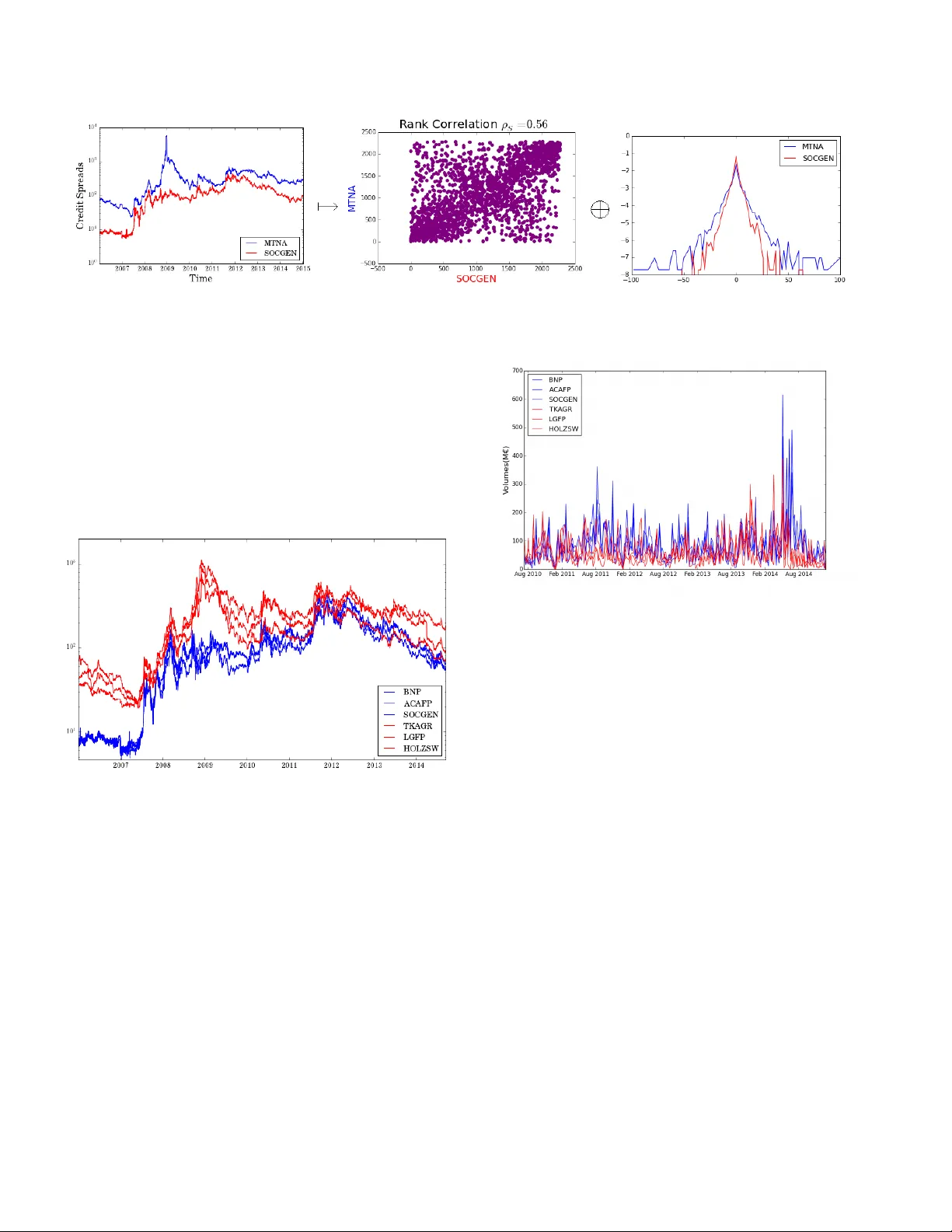
본 연구는 마코프 과정, 특히 랜덤 워크 형태의 금융 시계열을 자동으로 군집화하기 위한 새로운 비모수적 프레임워크를 제시한다. 기존의 군집화 방법은 주로 시계열의 평균·분산 같은 1차 통계량이나 상관계수에 의존하지만, 이러한 접근은 복잡한 의존 구조와 비정규 분포를 충분히 반영하지 못한다. 이를 해결하기 위해 저자들은 두 단계로 구성된 방법론을 개발하였다.
첫 번째 단계는 “비모수적 표현”이다. 연속형 실현값들의 i.i.d. 증분을 갖는 랜덤 워크 X=(X₁,…,X_N)를 두 부분으로 분리한다. 하나는 각 변수의 누적분포함수 G_Xi 로 구성된 주변분포 벡터 G_X, 다른 하나는 변환된 균등 변수 G_Xi(Xi) 로 구성된 의존성 벡터이다. 이 매핑 T:V^N→U^N×G^N은 일대일 대응이며, 정보 손실이 전혀 없다는 점에서 Sklar 정리와 유사하지만, 실제 데이터에 바로 적용 가능한 형태로 구현된다. 즉, 각 시계열을 “의존성 좌표”와 “분포 좌표” 두 개의 비모수적 특성으로 변환한다.
두 번째 단계는 거리 함수 d_θ의 정의이다. d_θ는 의존성 거리 d₁과 분포 거리 d₀의 가중합으로, 파라미터 θ∈
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기