효율적인 무향 토픽 모델 학습을 위한 알파NCE
초록
본 논문은 복제 소프트맥스(Replicated Softmax) 모델의 학습 효율성을 크게 향상시키기 위해 Noise Contrastive Estimate(NCE)를 기반으로 한 α‑NCE라는 새로운 추정기를 제안한다. 문서 길이와 가중 입력을 고려한 부분 노이즈 샘플링(PNS)과 균일 대비 추정(UCE)을 결합해 기존 대비 학습(Contrastive Divergence)보다 10~500배 빠른 학습 속도와 문서 검색·분류에서 경쟁력 있는 정확도를 달성한다.
상세 분석
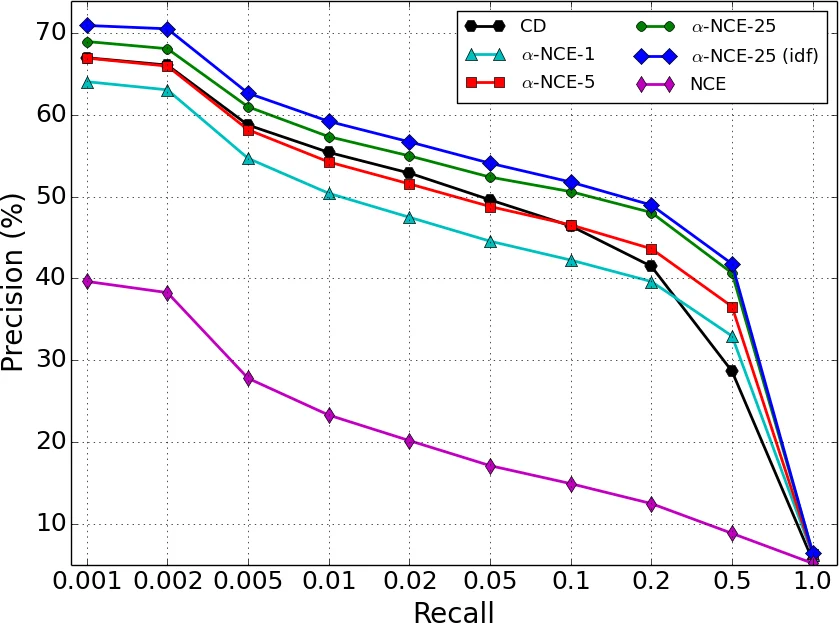
α‑NCE는 무향 토픽 모델인 Replicated Softmax Model(RSM)의 특수성을 고려하여 설계된 학습 알고리즘이다. 기존의 CD(Contrastive Divergence)는 이진 입력을 전제로 하며, RSM이 소프트맥스 가시 유닛을 사용해 단어를 다중범주형으로 표현하기 때문에 샘플링 비용이 급증한다. 특히 어휘 규모가 수만에 달할 경우 Gibbs 샘플링 단계마다 선형 시간 복잡도가 발생해 실용성이 떨어진다. 논문은 이러한 병목을 해소하기 위해 NCE를 기본 추정기로 채택한다. NCE는 정규화 상수 Z_D를 파라미터화해 비정규화 모델의 로그우도 대신 데이터와 인공 노이즈를 구분하는 이진 분류 문제로 변환한다. 여기서 핵심은 적절한 노이즈 분포를 선택하는데, 저자는 문서 수준에서 부분 노이즈를 삽입하는 PNS(Partial Noise Sampling) 방식을 제안한다. PNS는 원문에서 일정 비율(α)만큼 단어를 유지하고 나머지를 사전 확률 ˜p에 따라 무작위로 교체함으로써, 완전 노이즈(k=0)보다 데이터와 더 유사한 노이즈를 생성한다. 이는 NCE 이론에서 권장하는 “노이즈는 데이터와 충분히 가깝게”라는 조건을 만족시켜 학습 효율과 안정성을 동시에 높인다. 또한 문서 길이가 가변적인 문제를 해결하기 위해 UCE(Uniform Contrastive Estimate)를 도입한다. UCE는 로그비율 X(V)를 문서 길이 D에 대해 1/D 스케일링함으로써, 길이 차이에 의한 편향을 제거하고, 가중 입력(예: tf‑idf)에도 자연스럽게 확장할 수 있다. α‑NCE는 PNS와 UCE를 결합한 형태로, 파라미터 θ와 함께 각 문서 길이에 대한 정규화 상수 Z_cD를 고정값으로 두어 학습을 단순화한다. 실험에서는 20 Newsgroups와 IMDB 두 대규모 텍스트 코퍼스를 사용해, 어휘 크기 10020,000에 대해 CD와 α‑NCE의 실행 시간을 비교하였다. 결과는 α‑NCE가 CD보다 10배에서 500배까지 빠른 학습 속도를 보였으며, 특히 큰 어휘와 높은 노이즈 샘플(k)에서도 시간 증가가 완만했다. 성능 측면에서는 퍼플렉시티 대신 문서 검색의 정밀도‑재현율 곡선과 분류 정확도를 평가했는데, α‑NCE가 CD와 동등하거나 더 높은 MAP와 정확도를 기록했다. 특히 tf‑idf 가중 입력을 사용했을 때 가장 좋은 결과를 얻었으며, 이는 가중 입력이 토픽 특징을 더 풍부하게 만든다는 기존 연구와 일치한다. α 값에 대한 민감도 분석에서도 α가 0.30.5 사이일 때 최적의 성능을 보였으며, α가 1에 가까워질수록 노이즈가 데이터와 거의 동일해 학습이 불안정해지는 현상이 관찰되었다. 전체적으로 α‑NCE는 RSM뿐 아니라 더 복잡한 무향 심층 모델(예: Deep Boltzmann Machine)에도 적용 가능함을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기