금융 뉴스와 워드 임베딩, 딥러닝을 활용한 주가 변동 예측
초록
본 논문은 워드2벡(word2vec) 기반 키워드 추출과 딥 뉴럴 네트워크(DNN)를 결합해 금융 뉴스와 과거 가격 데이터를 동시에 활용함으로써 주가 상승·하락을 예측한다. 뉴스에서 추출한 Bag‑of‑Keywords, Polarity Score, Category Tag 세 가지 특징을 설계하고, 5,000개 종목의 상관관계 그래프를 통해 뉴스에 직접 언급되지 않은 종목까지 예측 범위를 확대한다. 실험 결과, 뉴스 기반 특징을 모두 결합했을 때 테스트 오류율이 43.13%로, 가격 정보만 사용한 베이스라인(48.12%)보다 크게 개선되었다.
상세 분석
이 연구는 기존의 시계열 기반 주가 예측에 텍스트 정보를 효과적으로 결합하는 방법을 제시한다. 먼저 과거 5일간의 종가와 그 일차·이차 차분을 정규화하여 가격 특징 벡터 P, ΔP, ΔΔP를 만든다. 텍스트 측면에서는 모든 기사 문장을 주식명 혹은 기업명이 포함된 문장으로 필터링하고, 날짜·주식별로 샘플을 구성한다. 키워드 추출은 word2vec으로 학습된 임베딩 공간에서 9개의 시드 단어(예: surge, fall 등)를 기준으로 코사인 유사도가 높은 상위 1,000개 단어를 선정하고, TF‑IDF 가중치를 부여해 1,000 차원의 Bag‑of‑Keywords(Bok) 벡터를 만든다.
Polarity Score(PS)는 각 키워드에 대해 긍정·부정 샘플에서의 PMI 차이로 계산하고, 구문 분석을 통해 키워드가 해당 주식의 주어인지 여부에 따라 부호를 조정한다. 이렇게 얻은 PS와 TF‑IDF를 곱해 또 다른 1,000 차원 벡터를 만든다. Category Tag(CT)는 사전 정의된 10개의 카테고리(신제품, 인수, 소송 등)에 대해 각 카테고리별 시드 단어를 임베딩 기반으로 확장하고, 샘플 내 해당 카테고리 단어 출현 횟수의 로그값을 사용해 10 차원 벡터를 만든다.
예측 모델은 4개의 은닉층(각 1,024 노드)과 ReLU 활성화, 출력층에 Softmax를 적용한 다층 퍼셉트론이다. 가격 특징만 사용한 베이스라인 대비, Bok+PS+CT를 모두 포함했을 때 테스트 오류율이 43.13%로 가장 낮았다.
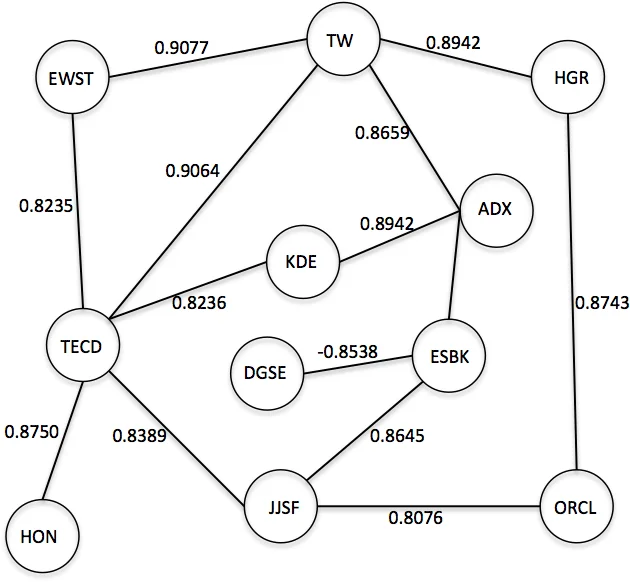
뉴스에 직접 언급되지 않은 종목에 대한 예측을 위해 5,000개 종목 간 상관계수를 기반으로 무방향 그래프를 구축하고, DNN 출력 벡터를 그래프 전파(Ax) 방식으로 확산시킨다. 전파 횟수를 조절하거나 신뢰도 임계값을 적용해 정확도와 커버리지를 trade‑off 할 수 있다. 실험에서는 임계값 0.9일 때 하루 평균 354개의 추가 종목을 52.44% 정확도로 예측했다.
전체적으로 이 논문은 (1) 임베딩 기반 키워드 자동 확장, (2) 구문 기반 극성 보정, (3) 카테고리별 이벤트 태깅, (4) 상관관계 그래프 전파라는 네 가지 기술적 기여를 통해 텍스트와 가격 데이터를 효과적으로 융합하고, 비교적 간단한 DNN 구조만으로도 의미 있는 성능 향상을 달성했다는 점이 주목할 만하다. 다만, 키워드 시드 선정의 주관성, 라벨링을 위한 다음 날 종가 사용에 따른 레이블 노이즈, 그리고 상관관계 그래프의 정적 특성 등은 향후 연구에서 보완될 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기