문맥을 고려한 대화 응답 생성 신경망 모델
초록
본 논문은 트위터 대화 데이터를 활용해, 이전 발화들을 문맥으로 인코딩하고 이를 기반으로 응답을 생성하는 두 종류의 동적 컨텍스트 생성 모델(DCGM‑I, DCGM‑II)을 제안한다. 기존 통계적 기계번역 기반 응답 생성 방식보다 BLEU·METEOR 점수와 인간 평가에서 일관된 향상을 보이며, 다중 참조 추출 기법을 통해 자동 평가의 신뢰성을 높였다.
상세 분석
이 연구는 대규모 비구조화 트위터 대화 코퍼스를 end‑to‑end 방식으로 학습 가능한 신경망 기반 응답 생성 시스템을 설계한다. 핵심은 Recurrent Neural Network Language Model(RLM)을 기반으로, 대화의 이전 발화(c)와 현재 메시지(m)를 연속적인 실수 벡터로 압축한 뒤, 이를 디코더 RLM에 바이어스로 제공하는 것이다.
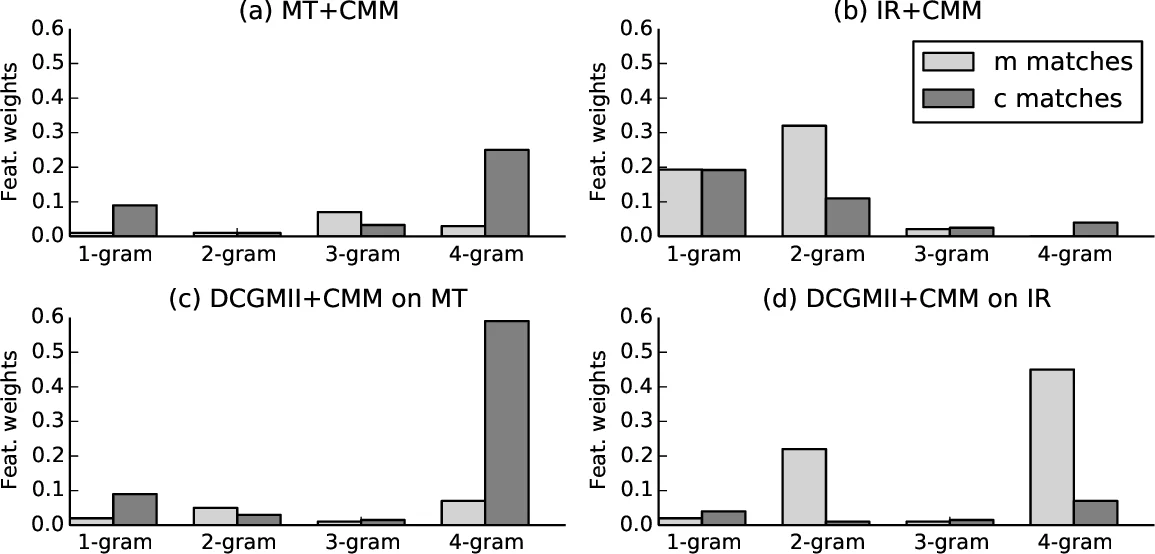
첫 번째 베이스라인인 RLMT는 c, m, r을 단순히 하나의 긴 시퀀스로 연결해 RLM을 학습한다. 하지만 긴 시퀀스는 장기 의존성 학습을 어렵게 하여 성능 저하 요인이 된다. 이를 보완하기 위해 제안된 DCGM‑I는 c와 m을 bag‑of‑words 형태로 합친 뒤, 다층 비선형 피드포워드 네트워크를 통해 고정 길이 컨텍스트 벡터 k_L을 생성한다. 이 벡터는 디코더 RLM의 은닉 상태 h_t에 매 시점마다 동일하게 더해져, 응답 생성 전 과정에 걸쳐 문맥 정보를 지속적으로 제공한다.
DCGM‑II는 DCGM‑I의 한계를 인식하고, c와 m을 별도의 임베딩으로 처리한 뒤 첫 번째 피드포워드 층에서 concat(병합)한다. 이렇게 하면 메시지와 컨텍스트 사이의 순서 의존성을 보존하면서도 각각의 의미적 특성을 별도로 학습할 수 있다. 두 모델 모두 컨텍스트 인코더와 디코더를 동시에 최적화함으로써, 전통적인 통계적 MT 시스템이 겪는 희소성 문제를 연속 표현을 통해 완화한다.
데이터 구축 단계에서는 127M 트위터 트리플을 수집하고, 빈도 기준과 사용자 일관성 조건을 적용해 29M 고품질 트리플을 추출했다. 이후 인간 평가를 통해 4점 이상(5점 척도)인 4,232개의 트리플을 선정, 2,118개를 튜닝, 2,114개를 테스트 셋으로 분리하였다. 자동 평가는 BLEU와 METEOR를 사용했으며, 단일 레퍼런스의 한계를 극복하기 위해 BM25 기반 IR을 이용해 다중 레퍼런스를 자동으로 채굴하고 인간이 검증하도록 설계했다.
실험 결과, DCGM‑II가 BLEU‑4에서 0.71, METEOR에서 0.21 점을 기록하며, 기존 MT 기반 모델(0.62/0.18)과 RLMT(0.66/0.20)보다 유의미하게 우수했다. 인간 평가에서도 DCGM‑II가 가장 높은 선호도를 얻었으며, 다중 레퍼런스를 활용한 BLEU 최적화가 인간 판단과 높은 상관관계를 보였다.
이 논문의 주요 기여는 (1) 문맥을 연속 벡터로 인코딩해 응답 생성에 직접 활용한 최초의 신경망 모델 제시, (2) 컨텍스트와 메시지를 구분해 처리하는 DCGM‑II 구조 도입, (3) 자동 다중 레퍼런스 추출 기법을 통해 응답 생성 평가의 신뢰성을 향상시킨 점이다. 한계로는 컨텍스트 길이를 단일 문장으로 제한한 점, 그리고 여전히 BLEU·METEOR와 인간 평가 사이의 완전한 일치가 보장되지 않는 점을 들 수 있다. 향후 연구에서는 더 긴 대화 흐름을 다루는 계층적 RNN, 외부 지식(시간, 위치 등) 통합, 그리고 대화 품질을 직접 최적화하는 강화학습 기반 접근이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기