잊혀지는 권리 자동화와 개인정보 보호를 위한 Oblivion 프레임워크
초록
Oblivion은 사용자가 자신의 개인정보가 포함된 웹 페이지를 자동으로 탐지·태깅하고, 법적 권리인 ‘잊혀질 권리’를 증명 가능한 형태로 검색 엔진에 제출하도록 지원하는 시스템이다. 신뢰된 디지털 신분증과 RSA 동형암호를 활용해 사용자의 신원과 데이터 소유권을 최소한의 정보만 노출하며 검증하고, 278건/초의 처리량을 보이며 대규모 배포가 가능함을 실험적으로 입증한다.
상세 분석
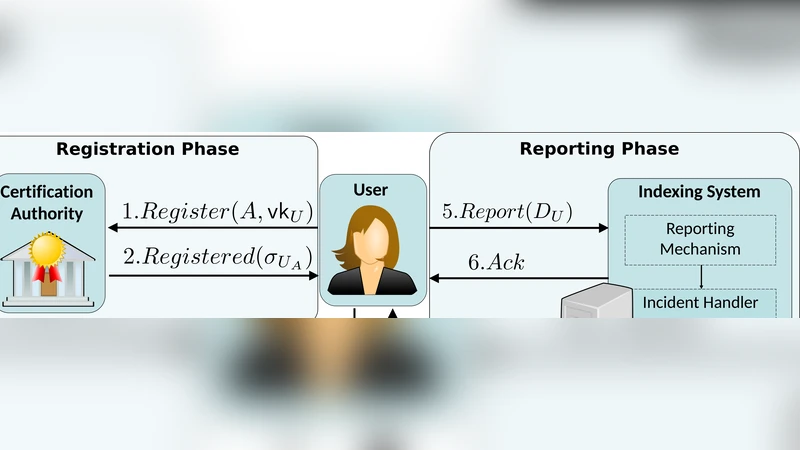
Oblivion은 현재 EU의 ‘잊혀질 권리’ 시행에서 발견되는 두 가지 핵심 문제, 즉(1) 사용자가 직접 모든 침해 링크를 수집·제출해야 하는 비효율성 및(2) 검색 엔진이 요청자의 적격성을 수동으로 판단해야 하는 비용 문제를 기술적으로 해결한다. 첫 번째 단계에서는 최신 자연어 처리(NLP)와 이미지 인식 모델을 이용해 사용자가 온라인에 노출된 텍스트·사진을 자동으로 식별한다. 여기서 중요한 점은 개인 식별 정보(PII)를 추출하면서도 사용자의 프라이버시를 침해하지 않도록 설계된 프라이버시‑프리저빙 파이프라인을 적용한다는 것이다. 두 번째 단계에서는 인증기관(CA)이 발행한 전자 신분증(여권, 전자 ID 등)의 서명된 속성을 활용한다. 이러한 서명 속성은 RSA 동형암호의 멀티플리케이션 특성을 이용해, OCP(Ownership Certification Party)가 다수의 사용자 인증서를 한 번의 연산으로 검증할 수 있게 한다. 즉, OCP는 사용자가 제시한 서명 속성과 공개된 웹 페이지의 메타데이터·본문을 비교해 사용자가 해당 페이지의 데이터 주체임을 증명한다. 이 과정에서 OCP는 사용자의 실제 신원 정보를 노출하지 않으며, 검색 엔진은 ‘사용자가 해당 페이지에 영향을 받는다’는 증거만을 받아들인다.
보안 모델은 최소 노출 원칙을 기반으로 한다. CA는 신뢰된 발급자이며, OCP는 신뢰 관계가 제한된 제3자(또는 검색 엔진 자체)로 가정한다. 외부 공격자는 재전송 공격이나 인증서 위조를 시도할 수 있지만, SSL/TLS와 키 폐기 메커니즘을 통해 이러한 위협을 완화한다. 또한, Oblivion은 법적 적합성 판단(데이터 보호 권리와 공공 이익의 균형)은 법원에 맡기고, 기술적 적격성 검증만을 자동화한다는 점에서 범위가 명확히 정의되어 있다.
성능 평가에서는 2.5 GHz 듀얼 코어 노트북에서 278 req/s의 처리량을 기록했으며, 이는 현재 구글·마이크로소프트·야후 등 주요 검색 엔진이 처리하는 요청 규모와 비교해 충분히 확장 가능함을 보여준다. 시스템은 텍스트와 이미지 두 종류의 데이터에 초점을 맞추었지만, 설계가 모듈식이므로 음성·동영상 등 다른 미디어 형식도 향후 통합이 가능하도록 설계되었다.
요약하면, Oblivion은 (1) 자동화된 개인정보 탐지, (2) 최소 정보 공개를 보장하는 암호학적 적격성 증명, (3) 높은 처리량을 제공하는 실용적인 프레임워크로, EU ‘잊혀질 권리’ 구현에 필요한 기술적 격차를 메우는 중요한 진전이다.
댓글 및 학술 토론
Loading comments...
의견 남기기