데이터 기반 누적 생물학을 위한 모델 결합 검색 엔진
본 논문은 기존의 키워드 기반 데이터베이스 검색을 넘어, 사전에 구축된 각 실험 데이터셋의 확률적 모델을 활용해 새로운 실험 데이터를 조합 모델로 분해하고, 가장 큰 기여를 하는 기존 데이터셋을 가중치 기반으로 빠르게 찾아내는 방법을 제안한다. 인간 유전자 발현 아틀라스에 적용한 결과, 조직·질병 정보보다 더 정교한 연관성을 발견했으며, 키워드 검색보다 높은 정밀도·재현율을 보였다. 또한, 검색 결과가 실제 논문 인용과 높은 일치를 보이며 데이…
저자: Ali Faisal, Jaakko Peltonen, Elisabeth Georgii
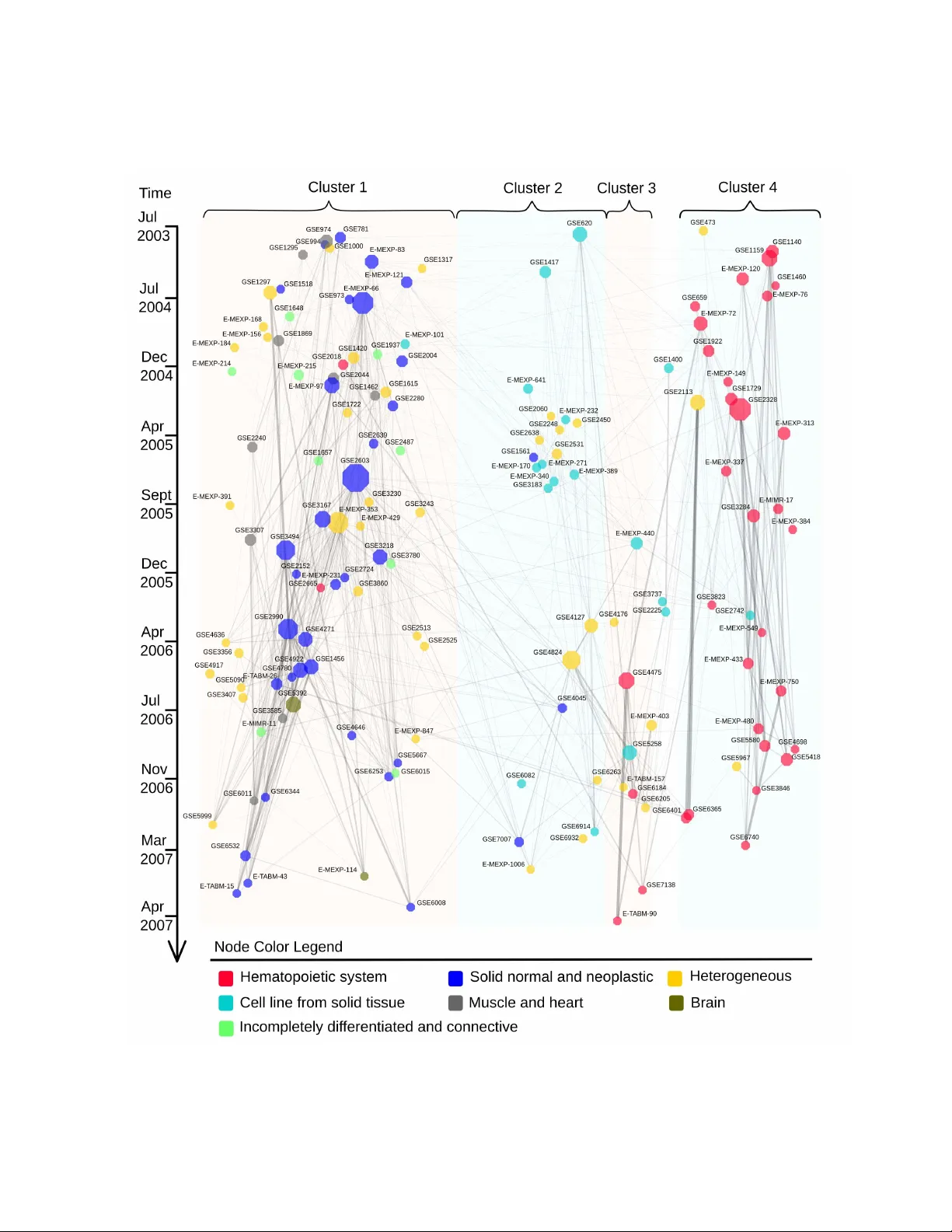
본 연구는 데이터‑드리븐 과학에서 급증하는 실험 데이터베이스를 효과적으로 활용하기 위한 새로운 검색 메커니즘을 제안한다. 기존의 키워드·오ント올로지 기반 검색은 연구자가 직접 어노테이션을 입력하거나 기존 라벨에 의존해야 하며, 실제 데이터 간의 통계적 유사성을 반영하지 못한다는 한계가 있다. 이를 극복하고자 저자들은 각 데이터셋을 사전에 확률적 생성 모델(M_s)로 요약하고, 새로운 실험 데이터(q)를 이들 모델들의 가중합(혼합 모델)으로 표현하는 ‘모델 기반 데이터셋 검색 엔진’을 설계하였다.
핵심 수식은 다음과 같다.
p({x_qi}|Θ_q)=∏_{i=1}^{N_q}
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기