APEnet 3D 토러스 네트워크의 28nm FPGA 기반 아키텍처 개선
초록
본 논문은 FPGA 기반 PCIe 확장 카드인 APEnet+의 최신 아키텍처 개량과 28 nm 공정 적용 결과를 제시한다. 주요 개선점은 PCIe 다중 DMA 엔진 도입, 하드웨어 TLB 구현, 오프보드 트랜시버 주파수 상승, 그리고 GPU‑to‑GPU 제로‑카피 RDMA 지원이다. 성능 평가에서는 작은 메시지에서 InfiniBand 대비 30 % 이하의 지연을 보였으며, 대역폭은 2.2 GB/s에 근접한다. 또한 결함 인식 메커니즘(LO|FA|MO)과 차세대 PCIe Gen3·56 Gbps 링크 설계 방향도 논의한다.
상세 분석
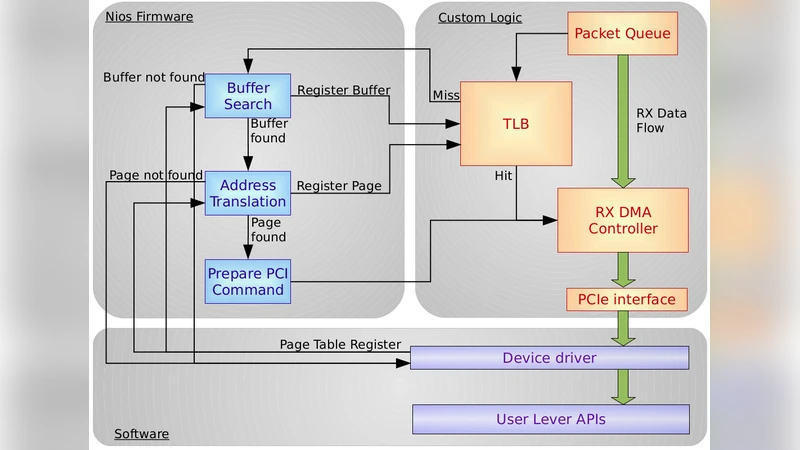
APEnet+는 기존에 6개의 34 Gbps 양방향 오프보드 링크와 PCIe X8 Gen2 인터페이스를 갖춘 맞춤형 인터커넥트이다. 논문에서는 세 가지 핵심 구조적 개량을 상세히 설명한다. 첫째, PCIe 측면에서 단일 DMA 엔진이 병목이 되는 문제를 해결하기 위해 두 개의 독립적인 DMA 엔진을 병렬로 운영하도록 설계하였다. 명령 큐를 프리패치 가능한 형태로 유지함으로써 여러 요청을 동시에 전송하고, 전송 완료 대기 시간을 겹치게 하여 최대 40 %의 전송 시간 감소를 기대한다. 둘째, 메모리 관리 단계에서는 가상‑물리 주소 변환을 담당하던 Nios II 코어를 우회하고, FPGA 내부에 제한된 엔트리를 보유한 하드웨어 TLB를 삽입하였다. 페이지 히트 시 Nios II가 완전히 배제되어 대역폭이 60 %까지 향상되는 것이 실험적으로 확인되었다. 셋째, 오프보드 인터페이스는 Altera(현 Intel) 트랜시버의 동작 주파수를 7.0 Gbps에서 14.1 Gbps 수준으로 끌어올리기 위한 신호 무결성 분석과 전송 제어 로직 최적화를 수행했다. 현재 구현에서는 채널당 2.6 GB/s, 전체 효율 0.784를 달성하였다. 성능 테스트에서는 GPU‑to‑GPU 제로‑카피 전송 시 P2P 모드를 이용해 8.2 µs의 라운드‑트립 지연을 기록했으며, 이는 InfiniBand 대비 약 50 % 이상 빠른 수치다. 대역폭 테스트에서는 CPU 메모리 읽기·쓰기와 GPU‑to‑CPU 쓰기에서 거의 링크 한계인 2.2 GB/s에 도달했지만, GPU 메모리 직접 읽기에서는 GPU 내부 메모리 서브시스템이 병목으로 작용한다는 점을 지적한다. 또한, 결함 인식 메커니즘인 LO|FA|MO를 하드웨어 레지스터와 워치독 프로토콜로 구현해 500 ms 주기의 감시 주기 내에 네트워크 전반의 결함을 실시간으로 파악할 수 있음을 보였다. 마지막으로 차세대 보드 설계에서는 PCIe Gen3(8 Gbps 레인, 128/130 비트 인코딩)와 56 Gbps QSFP+ 링크를 목표로 Stratix V GX 보드를 활용한 초기 실험 결과, 레인당 11.3 Gbps(채널당 45.2 Gbps)를 달성했다. 이러한 설계는 향후 Stratix 10 등 고성능 FPGA에 내장될 ARM 하드 IP와의 연동을 위한 AXI4 기반 인터페이스 전환을 전제로 한다. 전체적으로, 논문은 FPGA 기반 맞춤형 인터커넥트가 GPU 가속 HPC 시스템에서 비용 효율적인 대안이 될 수 있음을 실험적 데이터와 함께 설득력 있게 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기