친족 검색 효율과 오류율에 미치는 친척 영향
본 연구는 캘리포니아 주가 채택한 Myers 등(2011) 프로토콜을 시뮬레이션으로 재현하여, 13‑locus CODIS와 Y‑Filer Y‑염색체 마커를 이용한 친족 검색의 검출력과 오탐률을 평가한다. 1도 친척(부모‑자식, 형제)에서는 80‑99%의 높은 검출율을 보였지만, 사촌·반형제·2촌 등 보다 먼 친척이 Y‑염색체를 공유할 경우 3‑18% 정도의 확률로 1도 친척으로 오인될 위험이 존재한다. 특히 인종·민족별 데이터 편차로 인해 과소…
저자: Rori V. Rohlfs, Erin Murphy, Yun S. Song
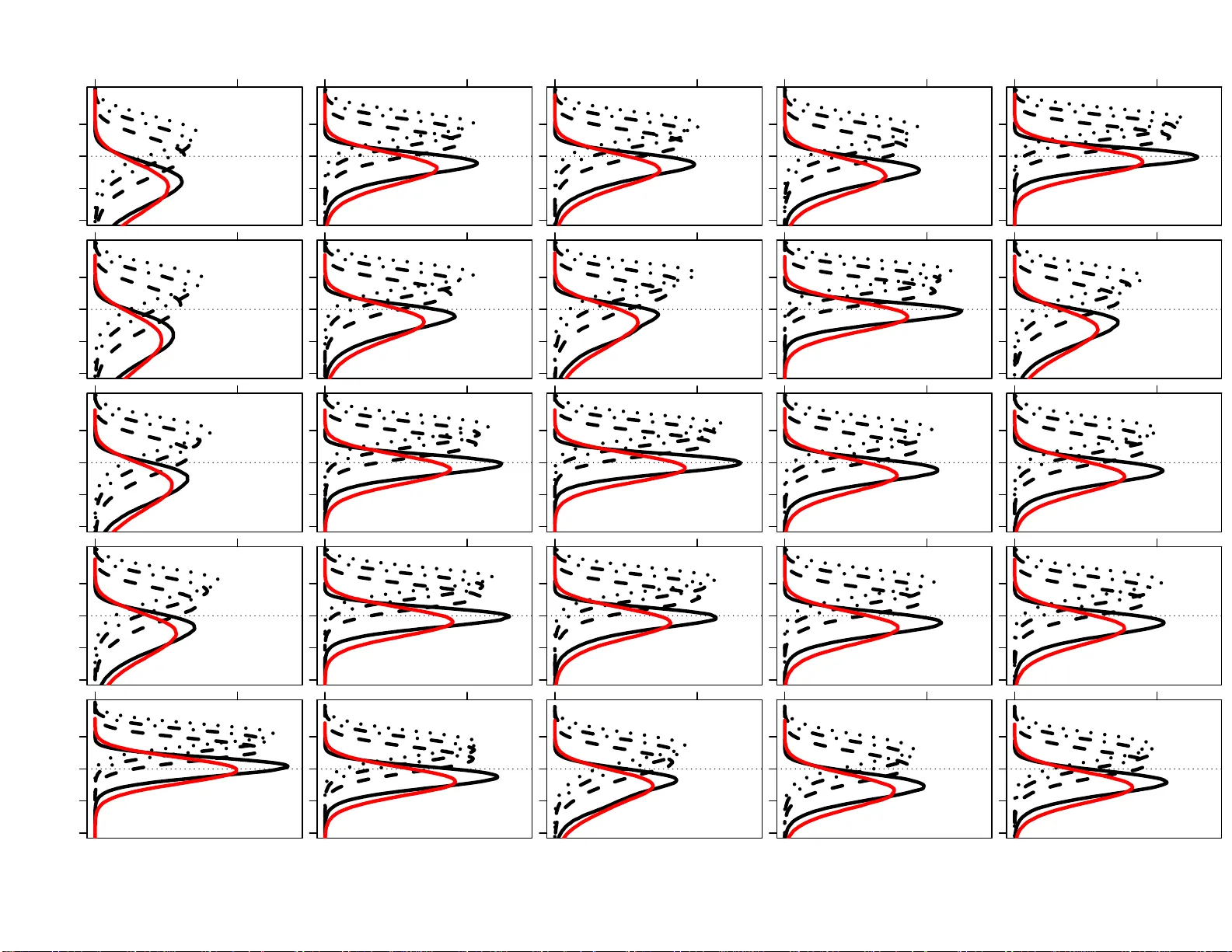
본 논문은 캘리포니아 주가 공식적으로 채택한 Myers 등(2011) 프로토콜을 기반으로, 친족 검색(familial searching)의 효율성과 오류율을 정량적으로 평가하기 위해 대규모 시뮬레이션 연구를 수행하였다. 연구자는 13‑locus CODIS STR과 Y‑Filer Y‑염색체 마커를 이용해, 인구통계학적으로 구분된 5개 인종군(베트남계 미국인, 아프리카계 미국인, 유럽계 미국인, 라틴계 미국인, 네이티브 아메리칸) 각각에 대한 대립유전자 빈도와 Y‑마커 빈도를 활용하였다.
시뮬레이션 설계는 두 부분으로 나뉜다. 첫 번째는 친척 관계를 가진 개인 쌍을 생성하는 것으로, 부모‑자식, 형제, 반형제, 사촌, 반사촌, 2촌 등 총 6가지 관계에 대해 각각 100만 쌍을 무작위로 생성하였다. 이때 Y‑염색체를 공유하도록 설계했으며, autosomal 마커는 θ=0.01(인구 구조 보정) 하에 생성하였다. 두 번째는 무관한 개인 쌍을 생성하는 것으로, 2000만 쌍을 시뮬레이션했으며, Y‑염색체는 실제 데이터에서 무작위 추출해 배경 공유율을 반영하였다.
각 쌍에 대해 Myers 프로토콜의 두 단계 LR(우도비) 계산을 수행하였다. 자동체 LR은 k0, k1, k2(IBD 0,1,2) 파라미터와 인구별 대립유전자 빈도를 이용해 구했으며, 세 가지 인구(아프리카계, 유럽계, 라틴계) 각각에 대해 별도 계산했다. Y‑염색체 LR은 해당 마커의 95% 신뢰구간 상한 빈도의 역수(1/p)로 정의하였다. 두 LR을 곱한 누적 LR이 사전에 정해진 임계값(예: 10⁶) 이상이면 해당 데이터베이스 엔트리를 ‘1도 친척 후보’로 판정한다.
결과는 다음과 같다. Y‑염색체를 공유하는 1도 친척(부모‑자식, 형제)의 경우, 누적 LR이 임계값을 초과하는 비율이 80%에서 99% 사이로 매우 높았다. 이는 캘리포니아 정책이 실제 현장에서 1도 친척을 효과적으로 찾아낼 수 있음을 시사한다. 반면, 무관한 개인이 1도 친척으로 오인될 확률은 0.01% 이하로 거의 없었다. 그러나 Y‑염색체를 공유하는 2도·3도 친척(사촌, 반사촌, 2촌)에서는 오탐률이 현저히 증가하였다. 인종별로 차이가 있었으며, 특히 아프리카계 미국인 집단에서는 Y‑마커의 다형성이 낮아 3%~18% 사이의 오탐 확률이 보고되었다. 라틴계와 베트남계에서도 유사한 수준의 오탐이 관찰되었다.
논문은 이러한 오탐 위험이 ‘즉각적인 가족’이 아닌 ‘더 먼 친척’까지 조사 대상으로 확대될 수 있음을 강조한다. 특히 캘리포니아와 연방 데이터베이스에 과다대표집단(흑인·라틴계 등)이 포함될 경우, 해당 집단의 친척들이 불필요하게 수사 대상이 될 가능성이 높아진다. 이는 형평성(equity)과 차별(discrimination) 논쟁을 촉발한다.
연구의 제한점으로는 첫째, 인구 라벨링이 사회적 구분에 의존해 과학적 정확성이 떨어진다. 둘째, Y‑염색체 마커는 변이와 재조합을 무시하고 단순히 동일성만을 가정했으며, 실제 현장에서는 돌연변이와 실험오차가 존재한다. 셋째, 시뮬레이션에 사용된 대립유전자 빈도와 Y‑마커 빈도가 제한된 표본(특히 네이티브 아메리칸)에서 추출돼 통계적 불확실성이 크다. 넷째, 실제 수사 과정에서 DNA 양·품질, 혼합물, 실험실 프로토콜 차이 등이 추가적인 변동 요인으로 작용할 수 있다.
윤리적·법적 논의 측면에서는, 오탐된 친척에 대한 후속 조사 절차와 개인정보 보호 방안이 구체적으로 제시되지 않았다. 또한, ‘가족 검색’이 인종·민족적 불균형을 심화시킬 위험에 대한 정책적 대응이 부족하다. 저자들은 다중 마커(예: 미토콘드리아 DNA, 추가 autosomal SNP) 결합을 통해 오탐률을 감소시키고, 인구학적 데이터베이스를 보다 투명하고 포괄적으로 구축할 것을 제안한다.
결론적으로, 캘리포니아식 가족 검색 프로토콜은 1도 친척 검출에 있어 높은 효율성을 보이지만, Y‑염색체 공유만을 기반으로 한 2도·3도 친척의 오탐 위험이 존재한다. 정책 입안자와 법 집행기관은 이러한 통계적 한계를 인식하고, 인종·민족별 데이터 편차를 보완하며, 추가 유전 마커와 엄격한 개인정보 보호 조치를 도입함으로써 형평성을 확보해야 한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기