GPU 가속 고차원 비선형 슈뢰딩거 방정식 통합 패키지 NLSEmagic
초록
NLSEmagic은 1·2·3 차원 비선형 슈뢰딩거 방정식을 고차 정확도 유한 차분 스킴으로 풀며, CUDA 기반 GPU 가속을 통해 MATLAB 환경에서 손쉽게 사용할 수 있는 오픈 소스 패키지이다. GPU 구현은 기존 CPU 직렬 코드 대비 수십 배 빠른 연산 속도를 제공하고, 클러스터 대비 비용 효율성이 높다.
상세 분석
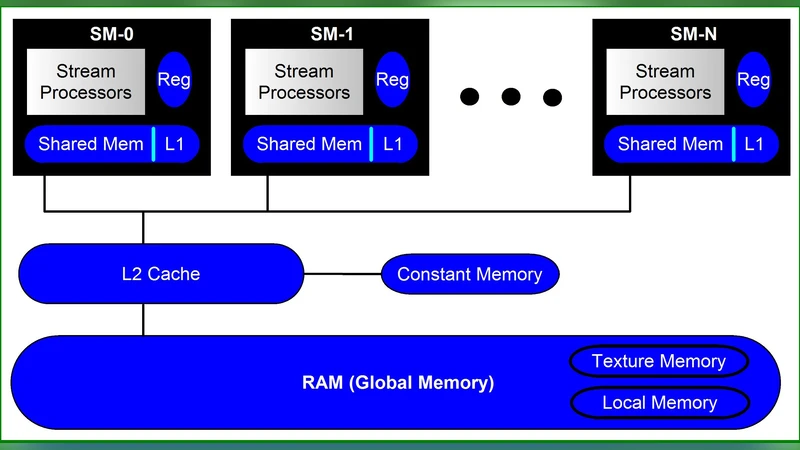
본 논문은 비선형 슈뢰딩거 방정식(NLSE)의 수치 해석에 있어 정확도와 실행 효율성을 동시에 만족시키는 새로운 소프트웨어 프레임워크인 NLSEmagic을 제안한다. 먼저 저자들은 고차 정확도를 확보하기 위해 4차·6차 컴팩트 유한 차분 스킴을 채택하였다. 이러한 스킴은 전통적인 중앙 차분보다 스펙트럼 폭이 넓어 파동 전파 시 발생하는 수치 분산을 크게 억제한다는 장점이 있다. 차원별로 1D, 2D, 3D 전용 커널을 설계했으며, 각 커널은 CUDA 스레드 블록을 이용해 공간 격자를 효율적으로 분할한다. 메모리 접근 패턴은 공유 메모리를 적극 활용해 전역 메모리 접근을 최소화함으로써 대역폭 병목을 완화하였다.
MATLAB과의 연동은 MEX 인터페이스를 통해 구현되었으며, 사용자는 MATLAB 스크립트 수준에서 초기 조건, 파라미터, 경계 조건 등을 지정하고, ‘nlse_step’와 같은 함수 호출만으로 GPU 가속 시뮬레이션을 수행할 수 있다. 이는 기존에 Fortran이나 C++ 기반 전용 코드를 직접 컴파일하고 실행해야 했던 복잡성을 크게 낮춘다. 또한 저자들은 다양한 하드웨어 환경(다양한 NVIDIA GPU 모델, CPU 아키텍처)에서의 이식성을 검증했으며, CUDA 버전과 MATLAB 버전에 대한 최소 요구 사항을 명시하였다.
성능 평가에서는 동일한 격자와 시간 스텝을 사용했을 때, GPU 구현이 CPU 직렬 구현 대비 20배에서 80배까지 속도 향상을 보였으며, 특히 3차원 시뮬레이션에서 그 차이가 극명하게 나타났다. 메모리 사용량 역시 공유 메모리와 스트리밍 멀티플렉서(SM) 활용을 통해 최적화되었으며, 대규모 격자(예: 512³)에서도 GPU 메모리 한계 내에서 안정적으로 실행된다.
또한, 저자들은 코드의 모듈성을 강조한다. 핵심 연산 커널은 독립적인 C 파일로 구성되어 있어 사용자가 필요에 따라 새로운 비선형 항이나 외부 포텐셜을 추가할 수 있다. 이와 동시에 풍부한 매뉴얼과 예제 스크립트가 제공되어 초보자도 빠르게 실험을 시작할 수 있다. 전체적으로 NLSEmagic은 고차 정확도, GPU 가속, MATLAB 친화성, 오픈 소스라는 네 가지 축을 균형 있게 결합함으로써 비선형 파동 연구에 필요한 실용적인 도구로 자리매김한다.