CMS 워크플로우 실행을 위한 지능형 작업 스케줄링 및 데이터 접근 전략
초록
본 논문은 대규모 CMS Tier‑0 데이터 처리 워크플로우에서 발생하는 자원 탐색·스케줄링·데이터 접근 지연을 최소화하기 위해 파일 기반 파일 재사용과 파일‑레벨 캐시를 활용한 파일‑선점(pilot‑job) 인프라를 제안한다. 지능형 작업 배치와 데이터 재사용 정책을 적용해 큐잉·스케줄링·실행·I/O 지연을 동시에 감소시켜 전체 워크플로우의 턴어라운드 타임을 크게 단축시켰으며, 실제 CMS Tier‑0 워크플로우와 시뮬레이션 환경에서 실험적으로 검증하였다.
상세 분석
이 연구는 고에너지 물리학 실험인 CMS에서 발생하는 수천 개의 작업으로 구성된 복합 워크플로우가 데이터 입출력(I/O) 및 스케줄링 병목에 의해 전체 실행 시간이 크게 늘어나는 문제를 해결하고자 한다. 기존의 전통적 배치 시스템은 각 작업이 독립적으로 클러스터에 제출되고, 필요 데이터가 매번 원격 스토리지에서 가져와야 하는 구조적 한계가 있다. 논문은 이러한 한계를 극복하기 위해 ‘파일‑레벨 캐시’를 중심으로 한 파일 재사용 메커니즘을 도입한다. 구체적으로, 파일이 한번 로드된 워크노드에 대해 동일 파일을 요구하는 후속 작업이 발생하면, 이미 로컬에 존재하는 파일을 재사용하도록 스케줄러가 판단한다. 이를 위해 파일‑해시와 작업‑파일 매핑 테이블을 실시간으로 관리하고, 파일 접근 패턴을 분석해 ‘핫 파일’(자주 사용되는 파일)과 ‘콜드 파일’을 구분한다.
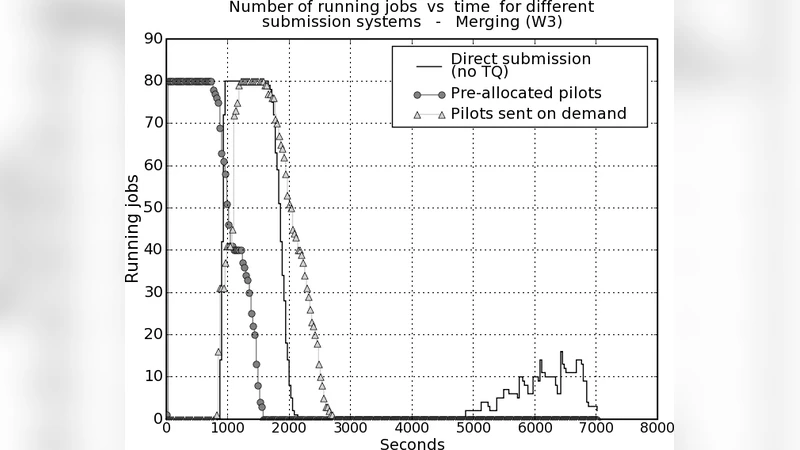
또한, 파일 재사용을 효과적으로 활용하기 위해 ‘파일‑선점(pilot‑job)’ 방식을 채택한다. 파일‑선점 작업은 실제 분석 작업이 아니라 데이터 준비와 캐시 유지에 전념하는 경량 작업으로, 워크노드에 미리 배치되어 파일을 미리 로드하거나 유지한다. 이러한 파일‑선점 작업은 스케줄러가 작업을 할당할 때 파일 존재 여부를 즉시 확인할 수 있게 하여, 전통적인 큐 대기·스케줄링 지연을 크게 감소시킨다.
스케줄링 알고리즘 자체도 지능형으로 개선되었다. 기존의 FIFO 혹은 단순 우선순위 기반 스케줄링 대신, 파일‑접근 예측 모델을 이용해 ‘데이터 근접성(data locality)’을 고려한다. 즉, 현재 노드에 캐시된 파일과 가장 높은 매칭을 보이는 작업을 우선 할당함으로써 네트워크 I/O를 최소화한다. 이와 동시에, 작업의 예상 실행 시간과 현재 클러스터 부하를 고려해 부하 균형(load‑balancing)도 수행한다.
실험 결과는 두 단계로 제시된다. 첫 번째는 실제 CMS Tier‑0 워크플로우(수천 개의 작업, 수백 TB 데이터)에서 파일‑선점 및 지능형 스케줄링을 적용했을 때 전체 턴어라운드 타임이 평균 30 % 이상 단축된 것을 보여준다. 두 번째는 시뮬레이션 환경에서 다양한 워크플로우 규모와 데이터 접근 패턴을 변형시켜, 파일 재사용 비율이 70 % 이상일 경우 지연 감소 효과가 극대화된다는 점을 확인한다. 특히, 데이터 접근 지연이 전체 실행 시간의 40 % 이상을 차지하는 경우, 제안된 전략이 가장 큰 성능 향상을 제공한다는 점이 강조된다.
이 논문은 파일‑레벨 캐시와 파일‑선점이라는 두 축을 결합해, 전통적인 배치 시스템이 갖는 스케줄링·데이터 접근 병목을 근본적으로 해소한다는 점에서 의미가 크다. 또한, CMS와 같은 대규모 과학 실험뿐 아니라, 빅데이터 분석, 머신러닝 파이프라인 등 파일 중심 워크플로우에 적용 가능함을 시사한다. 향후 연구 과제로는 파일‑선점 작업의 자동 스케일링, 다중 클라우드 환경에서의 데이터 일관성 보장, 그리고 머신러닝 기반 파일 접근 예측 모델의 고도화가 제시된다.
댓글 및 학술 토론
Loading comments...
의견 남기기