데이터 기반 물리적 사전학습을 위한 새로운 비음수 행렬분해 볼록 모델
초록
**
본 논문은 데이터 행렬 X의 열을 직접 사전(dictionary)으로 선택하고, (X \approx AS) 형태의 비음수 행렬분해를 볼록 최적화로 수행한다. (l_{1,\infty}) 정규화를 이용해 행 희소성을 강제함으로써, 잡음이 없는 경우 (l_{0}) 행 개수 최소화와 정확히 동등한 완화 모델을 제시한다. 잡음·이상치에 강인하도록 추가적인 정규화와 교대 최소화 초기화를 도입하고, 이를 고해상도 하이퍼스펙트럼 이미지의 엔드멤버 검출·풍부도 추정 및 NMR 블라인드 소스 분리에 적용한다.
**
상세 분석
**
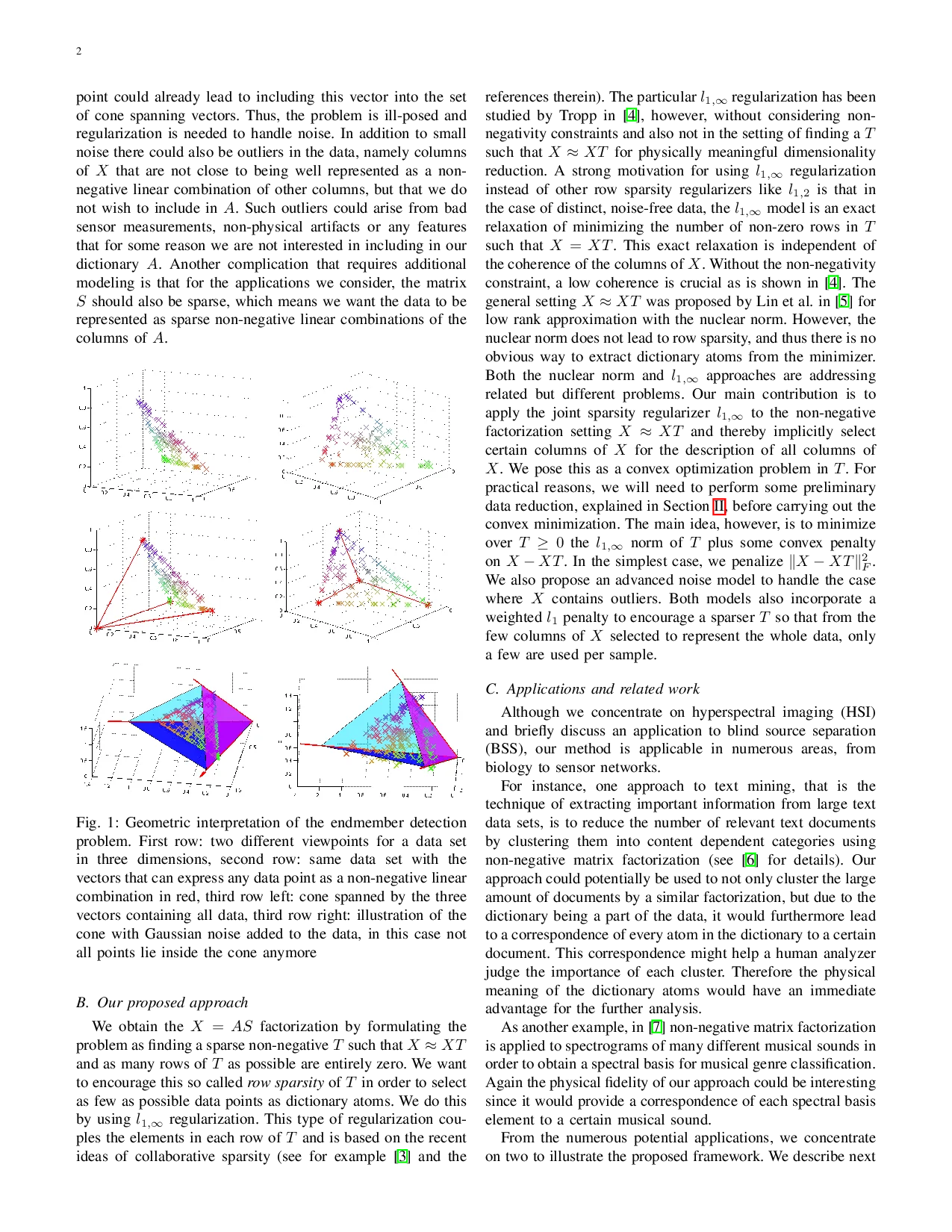
이 연구는 비음수 행렬분해(NMF)의 핵심 난제인 전역 최적해 탐색을 볼록 최적화로 전환한다는 점에서 혁신적이다. 기존 NMF는 교대 최소화(Alternating Minimization) 방식에 의존해 지역 최소에 머무를 위험이 크지만, 저자들은 “픽셀 순도 가정”(pixel‑purity assumption)을 이용해 사전 A의 열을 원본 데이터 X의 일부 열에 강제한다. 이렇게 하면 (X = X T) 형태의 자기 표현 모델을 구성할 수 있으며, (T) 의 행이 전부 0이면 해당 열은 사전에 포함되지 않는다. 따라서 (T) 의 행 희소성(row‑sparsity)을 최소화하는 것이 곧 최소 사전 선택 문제와 동치가 된다.
행 희소성 카운트를 직접 최소화하는 ( |T|{row‑0}) 는 NP‑hard이므로, 저자들은 (l{1,\infty}) 정규화 (|T|{1,\infty}= \sum_i \max_j |T{ij}|) 로 완화한다. 중요한 정리는 잡음이 없고 모든 열이 서로 다른 경우, 이 완화가 정확히 원문제와 동등함을 증명한다(즉, 최적 해는 동일한 행 집합을 선택한다). 이는 기존의 (l_{1,2}) 정규화와 달리 열 간 상관도(coherence)에 의존하지 않아, 고상관 데이터에서도 안정적으로 동작한다.
실제 데이터는 잡음·이상치가 존재하므로, 저자들은 두 가지 확장을 제안한다. 첫째, Frobenius 노름 (|X - X T|F^2) 를 손실 함수에 추가해 근사 정확도를 조절한다. 둘째, 행당 비음수 계수를 더 희소하게 만들기 위해 가중치 (l_1) 정규화 (\lambda |T|{1}) 를 포함한다. 이중 정규화는 (i) 사전 열 수를 최소화하고, (ii) 각 데이터 샘플이 선택된 사전 열을 적게 사용하도록 강제한다.
또한, 이상치에 강인한 변형 모델을 도입해, 큰 잔차를 가진 열을 자동으로 무시하도록 설계했다. 최적화는 ADMM(Alternating Direction Method of Multipliers) 기반의 효율적인 알고리즘으로 구현되며, 사전 선택 단계에서 차원 축소(pre‑processing)로 데이터 수를 크게 줄여 메모리·시간 복잡도를 완화한다.
응용 측면에서, 하이퍼스펙트럼 이미지(HSI)에서는 엔드멤버(물질 스펙트럼)와 풍부도(각 픽셀 내 물질 비율)를 동시에 추정한다. 픽셀 순도 가정이 실제 HSI에 잘 부합하므로, 선택된 사전은 물리적으로 의미 있는 스펙트럼을 그대로 제공한다. 실험 결과, 제안 모델은 기존 VCA, N-FINDR, 그리고 전통 NMF 대비 더 적은 엔드멤버 수로 동일하거나 더 높은 재구성 정확도를 달성한다. NMR 블라인드 소스 분리 실험에서도, 사전이 실제 혼합 스펙트럼에 포함된 경우 정확한 소스 복원을 보여, 모델의 일반성을 입증한다.
요약하면, 이 논문은 (1) 데이터 자체를 사전으로 활용해 물리적 해석 가능성을 확보하고, (2) (l_{1,\infty}) 정규화를 통한 정확한 볼록 완화로 전역 최적해를 보장하며, (3) 잡음·이상치에 대한 견고한 확장과 효율적인 최적화 알고리즘을 제공한다는 점에서 NMF·딕셔너리 학습 분야에 중요한 기여를 한다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기