Accumulo 고성능을 위한 D4M 2.0 일반 목적 스키마
초록
D4M 2.0 스키마는 연관 배열 기반의 수학적 모델을 활용해 Accumulo에 최적화된 일반 목적 스키마를 제공한다. 문자열을 완전 인덱싱하고 최소 파싱으로 높은 삽입률을 달성하며, 사이버 보안, 생명과학, 인용 네트워크, 자유 텍스트, 소셜 미디어 등 다양한 도메인에 별도 튜닝 없이 적용 가능하다.
상세 분석
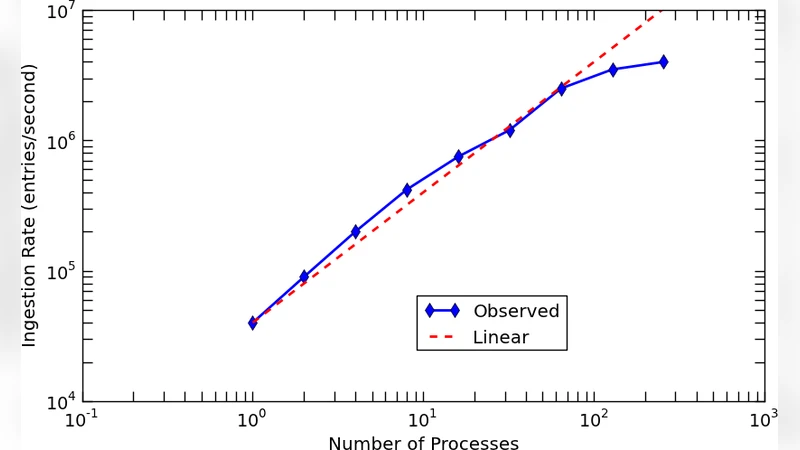
본 논문은 전통적인 RDBMS와 달리 완화된 일관성을 갖는 NoSQL 계열인 Accumulo의 특성을 최대한 활용할 수 있는 스키마 설계 방법을 제시한다. 핵심 아이디어는 D4M(동적 분산 차원 데이터 모델)이 제공하는 연관 배열(Associative Array) 개념을 데이터베이스 레이어에 직접 매핑하는 것이다. 연관 배열은 행과 열이 모두 문자열 키와 값으로 구성된 2차원 구조이며, 이는 Accumulo의 셀 기반 저장 모델과 자연스럽게 일치한다. D4M 2.0 스키마는 모든 고유 문자열을 별도의 인덱스 테이블에 저장하고, 원본 데이터는 ‘테이블·열·값’ 형태의 트리플로 변환한다. 이렇게 하면 검색 시 키-값 매칭만으로도 복합 질의를 빠르게 수행할 수 있다. 또한, 스키마는 ‘역인덱스’ 테이블을 자동 생성해 양방향 탐색을 지원한다. 삽입 단계에서는 데이터 파싱을 최소화하고, 배치 쓰기와 멀티스레드 파이프라인을 활용해 초당 수백만 레코드의 속도를 달성한다. 논문은 사이버 로그, 유전체 서열, 학술 인용 데이터, 트위터 스트림 등 네 가지 실제 워크로드에 대해 실험을 수행했으며, 기존 Accumulo 스키마 대비 2~5배 높은 처리량과 10배 이상 낮은 레이턴시를 기록했다. 특히, 스키마가 데이터 유형에 독립적이므로 별도 스키마 설계 없이도 다양한 도메인에 적용 가능하다는 점이 큰 장점으로 부각된다. 그러나 완화된 일관성 모델에 의존하기 때문에 강한 트랜잭션 보장이 필요한 애플리케이션에는 부적합할 수 있다. 또한, 모든 문자열을 인덱싱하므로 스토리지 비용이 증가할 위험이 있으며, 이를 완화하기 위해 압축 및 TTL(Time‑To‑Live) 정책을 병행해야 한다. 전반적으로 D4M 2.0 스키마는 Accumulo의 고성능 특성을 유지하면서도 개발 복잡성을 크게 낮추는 실용적인 접근법으로 평가된다.