큐 기반 분산 자원 제어를 이용한 지연 민감형 2홉 MIMO 협동 시스템
초록
본 논문은 소스와 릴레이의 버퍼링을 활용해 반이중 제약을 완화하고, 각 노드의 채널 상태 정보(CSI)와 큐 상태 정보(QSI)만을 이용한 분산형 두 단계 경매 제어 정책을 제안한다. 평균비용 무한 horizon 마코프 결정 과정(MDP)을 근사하기 위해 가치함수를 노드별 선형 합으로 표현하고, 온라인 확률적 학습을 통해 파라미터를 추정한다. 제안 기법은 복잡도는 크게 낮추면서도 중대 트래픽 상황에서 전역 최적성을 보장한다.
상세 분석
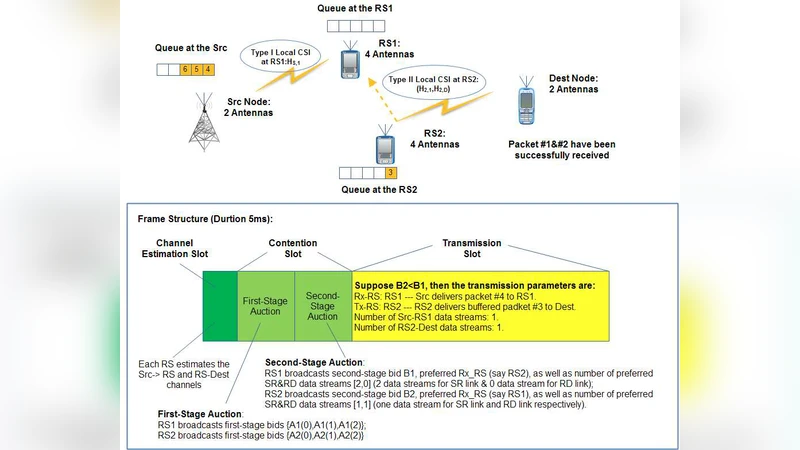
이 연구는 2홉 MIMO 협동 네트워크에서 반이중(half‑duplex) 제약으로 인한 스루풋 손실을 완화하기 위해 릴레이에 버퍼를 도입하는 접근을 채택한다. 버퍼링은 소스와 릴레이 간 전송 타이밍을 비동기화시켜, 소스가 데이터를 전송하고 릴레이가 수신하는 동시에 다른 릴레이가 전송을 수행하도록 허용함으로써 스펙트럼 효율을 크게 향상시킨다. 그러나 버퍼가 도입되면 각 노드의 큐 길이가 시스템 상태에 직접적인 영향을 미치게 되며, 이는 전통적인 CSI‑only 기반 스케줄링 기법으로는 다루기 어려운 복합적인 상호작용을 초래한다.
저자들은 이러한 복합성을 평균비용 무한 horizon MDP 모델로 정형화한다. 상태공간은 소스와 모든 릴레이의 QSI와 CSI의 조합으로 정의되며, 행동공간은 전송 전력, 안테나 선택, 그리고 릴레이 선택 등을 포함한다. 베벨 방정식의 정확한 해는 차원 폭발(curse of dimensionality) 때문에 실용적이지 않다. 따라서 논문은 가치함수를 “노드별 가치함수의 합”이라는 선형 구조로 근사한다. 이 근사는 각 노드가 자신의 로컬 상태만을 기반으로 가치 추정을 수행하도록 하여, 중앙집중식 연산을 완전히 배제한다.
근사된 가치함수를 이용해 두 단계 두 승자 경매(two‑stage two‑winner auction) 메커니즘을 설계한다. 첫 번째 단계에서는 각 릴레이가 자신의 QSI와 CSI에 기반해 제안 가격을 제시하고, 두 번째 단계에서는 소스가 제안된 가격과 자신의 QSI를 종합해 최적의 릴레이와 전송 파라미터를 선택한다. 이 과정은 완전 분산이며, 각 노드가 교환해야 하는 메시지는 가격 정보 정도로 제한되어 통신 오버헤드가 최소화된다.
또한, 근사 파라미터를 실시간으로 학습하기 위해 확률적 근사(stochastic approximation) 이론에 기반한 온라인 학습 알고리즘을 제안한다. 이 알고리즘은 시간에 따라 관측된 즉시 보상과 상태 전이를 이용해 파라미터를 점진적으로 업데이트하며, 논문은 수렴 조건을 엄격히 증명한다. 특히, “heavy‑traffic” 조건 하에서는 학습된 정책이 원래 MDP의 전역 최적 정책과 일치함을 보인다.
기술적 기여는 크게 네 가지로 요약된다. 첫째, 릴레이 버퍼링을 통한 반이중 페널티 감소 효과를 정량적으로 분석하고, 이를 MDP 모델에 통합하였다. 둘째, 가치함수의 선형 근사 구조를 도입해 복잡도를 다항식 수준으로 낮추었다. 셋째, 두 단계 경매 기반의 완전 분산 제어 정책을 설계하여 로컬 CSI/QSI만으로 최적 결정을 가능하게 했다. 넷째, 온라인 확률적 학습을 통해 근사 파라미터를 실시간으로 적응시킴으로써, 환경 변화에 강인한 제어를 구현하였다. 실험 결과는 제안 기법이 기존 중앙집중식 최적 정책에 근접하면서도 연산·통신 비용이 크게 감소함을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기