불완전 데이터의 주변 가능도 근사 효율적 방법
본 논문은 베이지안 네트워크에서 관측이 누락된(불완전) 데이터에 대한 주변 가능도(marginal likelihood)를 추정하기 위한 여러 비대칭 근사법을 비교한다. 라플라스 근사, BIC/MDL, Draper, 그리고 Cheeseman‑Stutz(CS) 방식을 실험적으로 평가한 결과, CS 점수가 가장 높은 정확도를 보였으며, BIC/MDL은 가장 부정확하고 단순 모델에 편향되는 경향이 있음을 확인하였다.
저자: David Maxwell Chickering, David Heckerman
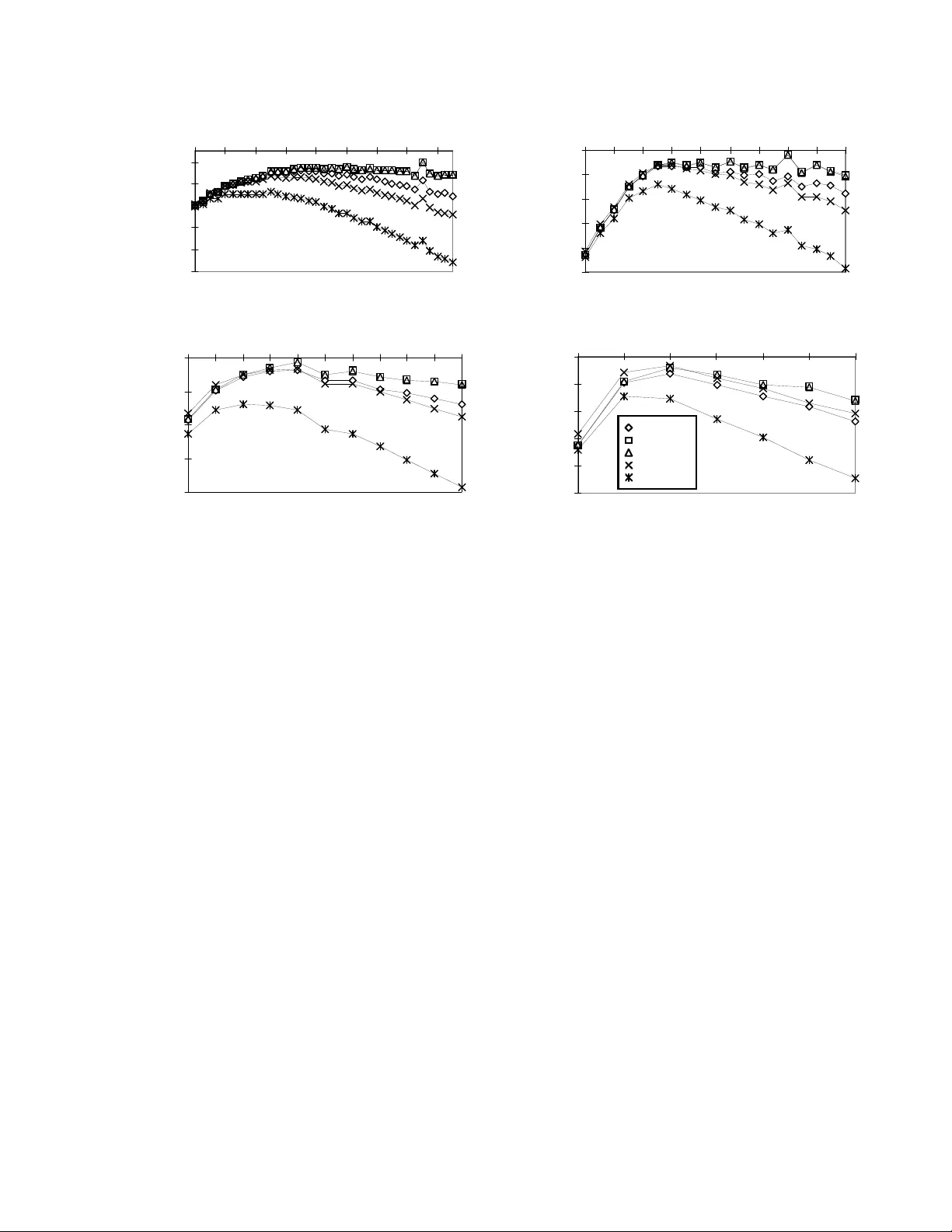
본 논문은 베이지안 네트워크 구조 학습에서 데이터가 불완전(관측 누락)할 때 주변 가능도(marginal likelihood)를 어떻게 효율적으로 근사할 수 있는지를 체계적으로 조사한다. 먼저 베이지안 학습 프레임워크를 소개하면서, 완전 데이터일 경우 Dirichlet 사전과 파라미터 독립성 가정 하에 베이즈 디리클레(BD) 점수를 정확히 계산할 수 있음을 설명한다. 그러나 관측이 누락된 경우 적분이 일반적으로 불가능해지므로, 여러 비대칭 근사법이 필요함을 강조한다.
다음으로 네 가지 주요 근사법을 상세히 전개한다.
1. **라플라스 근사**
- 사후분포 p(θ|D,S) 를 다변량 정규분포로 근사하고, MAP 추정값 ˜θ와 해시안 행렬 A를 이용해 로그 주변 가능도를
log p(D|S) ≈ log p(D|˜θ,S) + log p(˜θ|S) + (d/2)·log(2π) – (1/2)·log|A| 로 표현한다.
- 정규성 가정 하에 오차는 O(1/N)이며, 정확도가 가장 높지만 해시안 계산이 비용이 크다.
2. **BIC/MDL**
- 라플라스 식에서 N에 비례하는 항(log p(D|˜θ,S))과 차원 벌칙항(d/2·log N)만 남겨,
log p(D|S) ≈ log p(D|θ̂,S) – (d/2)·log N 로 근사한다.
- 사전 정보를 완전히 배제하고 O(1) 수준의 오차를 갖지만, 작은 표본에서 과도한 단순화 경향이 있다.
3. **Draper 근사**
- BIC에 상수항 d/2·log(2π) 를 추가하여
log p(D|S) ≈ log p(D|θ̂,S) – (d/2)·log N + (d/2)·log(2π) 로 만든다.
- 이론적으로 BIC와 동일한 asymptotic 정확성을 유지하면서, 실험에서는 BIC보다 약간 개선된 성능을 보인다.
4. **Cheeseman‑Stutz (CS) 및 MLED**
- EM 알고리즘을 이용해 기대 충분통계량 E(N_ijk|θ̂,S)를 계산하고, 이를 완전 데이터 D′처럼 취급해 로그 가능도 log p(D′|S)를 구한다.
- MLED는 단순히 log p(D′|S) 를 사용하지만 차원 보정이 없어 asymptotic correctness가 부족하다.
- CS는 MLED에 차원 보정과 원본 데이터 로그 가능도 보정을 더해,
log p(D|S) ≈ log p(D′|S) – log p(D′|θ̂,S) + (d′/2)·log N + log p(D|θ̂,S) – (d/2)·log N 로 정의한다.
- 이 방식은 기대 충분통계량을 이용해 불완전성을 보정하면서도 계산량은 EM 한 번이면 충분해 효율적이다.
논문은 이러한 근사법들을 실제 실험에 적용한다. 실험 설정은 숨겨진 루트 노드를 가진 이산 나이브 베이즈 모델을 사용해 합성 데이터를 생성하고, 다양한 샘플 크기와 숨김 비율을 변동시켰다. 각 모델에 대해 라플라스 근사를 “gold standard”로 삼고, BIC, Draper, MLED, CS 점수를 비교하였다. 주요 결과는 다음과 같다.
- **BIC/MDL**은 가장 큰 편향을 보이며, 특히 복잡한 모델을 과소평가해 지나치게 단순한 구조를 선택한다.
- **Draper**는 BIC보다 정확도가 높지만, 여전히 라플라스와 차이가 있다.
- **MLED**는 계산은 빠르지만 차원 보정이 없어서 큰 표본에서는 정확도가 떨어진다.
- **CS**는 라플라스와 거의 동일한 로그 주변 가능도 값을 제공하며, 가장 신뢰할 수 있는 근사법으로 평가된다.
또한, 계산 복잡도 측면에서 CS와 Draper는 EM 기반 MAP/ML 추정만 필요하므로 라플라스보다 훨씬 효율적이며, 대규모 데이터셋에서도 실용적이다. 논문은 이러한 결과를 바탕으로, 베이지안 네트워크 구조 학습 시 불완전 데이터에 대해 CS 점수를 기본 선택지로 권고하고, BIC/MDL은 초기 탐색 단계에서만 제한적으로 사용할 것을 제안한다. 마지막으로, 향후 연구 방향으로는 연속형 변수와 혼합형 모델에 대한 CS 확장, 그리고 고차원 구조 탐색에 대한 효율적인 최적화 알고리즘 개발을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기