다변량 조건부 이상치 탐지
초록
본 논문은 다차원 이진 레이블을 갖는 데이터에서, 입력 변수(컨텍스트)와 레이블 간의 조건부 관계를 모델링한 뒤, 각 레이블 차원에 대한 확률값을 벡터 형태로 변환하여 새로운 공간에서 이상치 점수를 계산하는 MCODE 방법을 제안한다. 클래스 체인 기반 확률 모델을 이용해 출력 공간을 분해하고, 희소·밀집형 이상치 모두를 효과적으로 탐지함을 실험을 통해 입증한다.
상세 분석
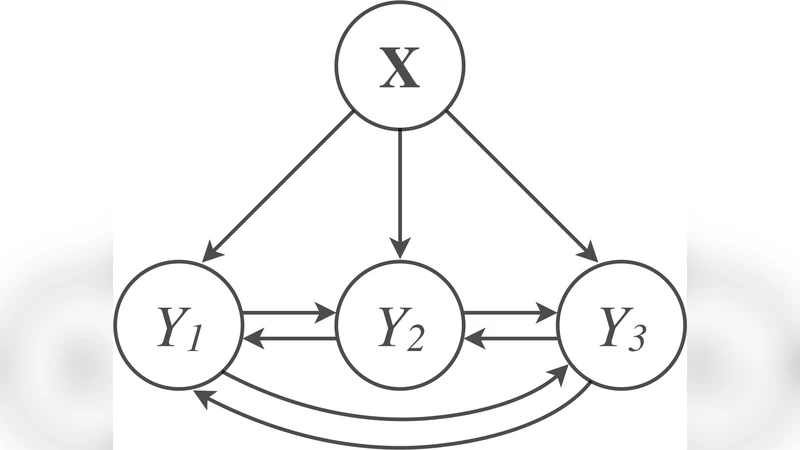
MCODE는 다변량 조건부 이상치 탐지라는 비교적 새로운 문제 설정에 대한 실용적인 해결책을 제시한다. 기존의 대부분 이상치 탐지 기법은 전체 특성 공간을 대상으로 하는 ‘무조건적’ 방법에 머물러, 컨텍스트에 따라 정상·비정상이 달라지는 상황을 제대로 포착하지 못한다. 이 논문은 이러한 한계를 극복하기 위해 (1) 조건부 확률 모델 P(Y|X)를 학습하고, (2) 학습된 모델을 이용해 각 레이블 차원별 사후 확률 P(Y_i|X, Y_{π(i)})를 추출한 뒤, 이를 d‑차원의 확률 벡터로 변환한다는 두 단계 전략을 채택한다.
핵심 기술은 클래스 체인(classifier chain) 분해이다. 다차원 이진 레이블 Y=(Y₁,…,Y_d)를 순차적으로 조건화함으로써, 복잡한 다변량 분포를 d개의 단일 레이블 예측기로 나눈다. 각 예측기는 입력 X와 이전 레이블들의 값 Y_{π(i)}를 특징으로 사용해 확률값을 출력한다. 이렇게 얻은 확률값들은 서로 독립적인 스코어가 아니라, 레이블 간 의존성을 반영한 연속적인 정보 흐름을 제공한다.
이후 MCODE는 변환된 확률 벡터에 다양한 이상치 점수 함수를 적용한다. 논문에서는 (a) 개별 차원의 로그 확률 합계, (b) 전체 벡터의 밀도 기반 점수, (c) 차원별 편차를 강조하는 스코어 등 여러 기준을 실험적으로 비교한다. 특히 희소형 이상치(몇몇 차원만 비정상)와 밀집형 이상치(다수 차원에서 비정상)가 동시에 존재할 때, 개별 차원 스코어와 전체 벡터 스코어를 조합함으로써 두 상황 모두 높은 탐지율을 유지한다는 점이 주목할 만하다.
모델 학습 단계에서는 훈련 데이터가 거의 이상치가 없다고 가정한다. 이는 기존 GMM 기반 조건부 모델이 EM 알고리즘으로 복잡하고 확장성이 낮은 것과 대비된다. 클래스 체인 방식은 각 레이블에 대해 독립적인 이진 분류기를 학습하므로, 대규모 데이터와 고차원 레이블에도 효율적으로 적용 가능하다. 또한, 확률값을 직접 활용함으로써 레이블 차원별 ‘낮은 확률’ 상황을 정밀하게 포착할 수 있어, 기존 방법이 놓치기 쉬운 미세한 이상치도 탐지한다.
실험에서는 이미지 태깅, 문서 키워드 할당, 의료 진단 등 다양한 다변량 레이블 데이터셋에 대해 인위적으로 이상치를 삽입하였다. 삽입 비율을 1%에서 20%까지 변화시키면서 MCODE는 높은 AUC와 낮은 false‑positive rate를 유지했으며, 특히 희소형 이상치에 대해 기존 LOF·One‑Class SVM보다 월등히 좋은 성능을 보였다. 이는 변환된 확률 공간이 실제 데이터의 ‘정상적’ 조건부 분포를 잘 반영하고, 이상치가 발생했을 때 해당 차원의 확률값이 급격히 감소하는 특성을 효과적으로 이용했기 때문이다.
요약하면, MCODE는 (1) 조건부 확률 모델을 클래스 체인으로 효율적으로 학습하고, (2) 이를 확률 벡터라는 새로운 무조건적 공간으로 변환한 뒤, (3) 다양한 스코어링 기법으로 이상치를 탐지한다는 일련의 흐름을 통해, 기존 무조건적 방법이 놓치기 쉬운 컨텍스트 의존적 이상치를 정밀하게 식별한다.
댓글 및 학술 토론
Loading comments...
의견 남기기