다차원 스케일링 기반 헤비안·안티헤비안 신경망으로 구현하는 온라인 주성분 서브스페이스 학습
본 논문은 스트리밍 데이터의 차원 축소를 위해 전통적인 재구성 오차 대신 고전적 다차원 스케일링(CMDS) 비용 함수를 최소화한다. 비용 함수를 온라인 형태로 전개하고, 좌표 하강(비동기)과 Jacobi 반복(동기) 두 가지 방법으로 신경망 업데이트 규칙을 도출한다. 결과적으로 전-시냅스 가중치는 Hebbian, 후-시냅스 가중치는 anti‑Hebbian 로만 구성된 로컬 학습 규칙을 갖는 단일 층 네트워크가 얻어지며, 가중치는 입력 데이터의 …
저자: Cengiz Pehlevan, Tao Hu, Dmitri B. Chklovskii
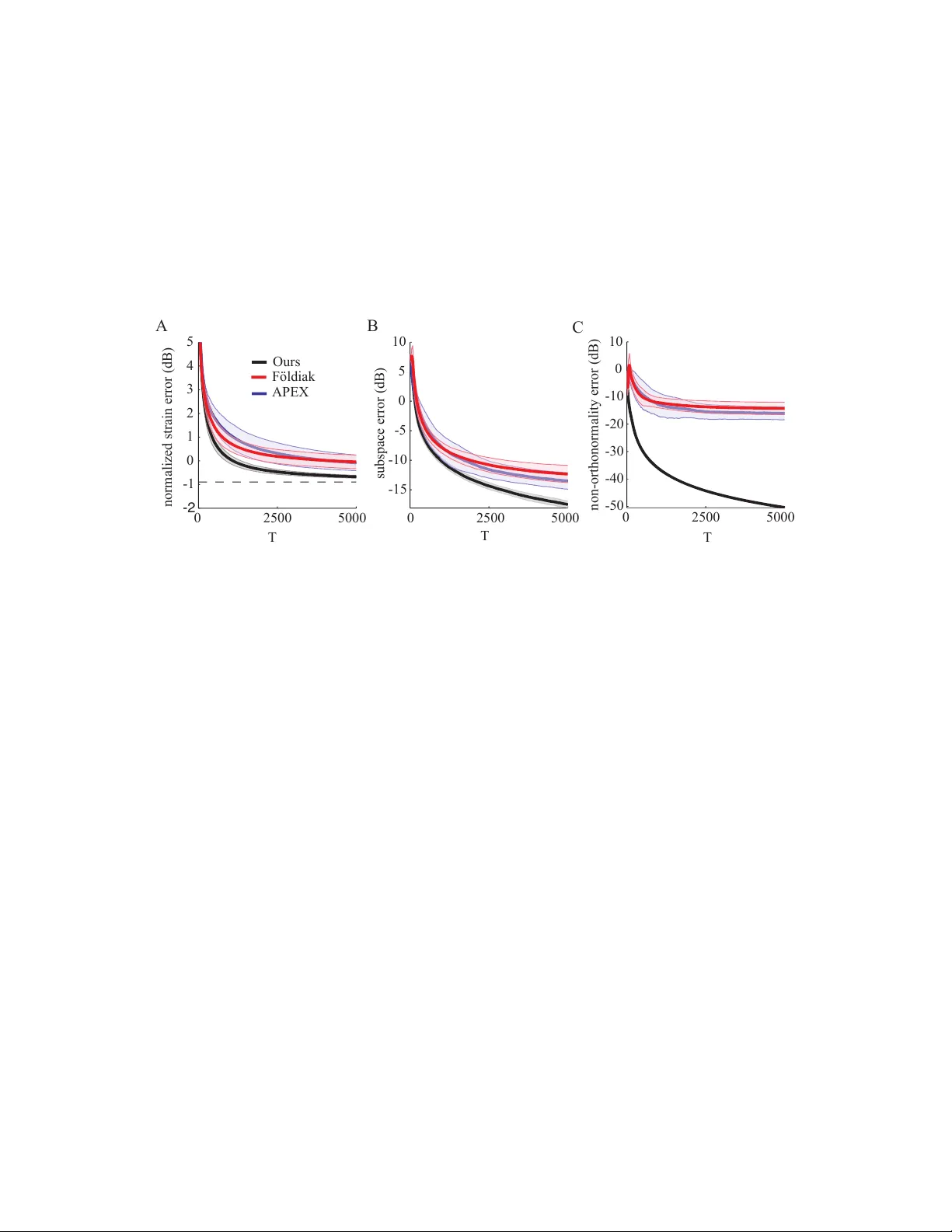
본 논문은 초기 감각 처리 과정에서 스트리밍 입력 데이터를 차원 축소하는 신경망 모델을 제안한다. 기존의 PCA 기반 온라인 알고리즘은 주성분 서브스페이스를 학습하지만, 비용 함수를 최소화하는 과정에서 비지역적 가중치 업데이트가 필요해 생물학적 타당성이 부족했다. 저자들은 이러한 격차를 메우기 위해, 전통적인 재구성 오차 대신 고전적 다차원 스케일링(CMDS)의 ‘스트레인’ 비용 ‑‖XᵀX‑YᵀY‖²_F 를 사용한다. CMDS는 입력 데이터 간의 유클리드 거리(또는 내적)를 보존하면서 저차원 좌표를 찾는 방법으로, 그 최적 해는 입력 공분산 행렬의 상위 고유벡터가 span 하는 서브스페이스와 동일하다.
스트리밍 상황에 맞게 비용을 온라인 형태로 전개하면, 현재 시점 T에서의 출력 y_T 만을 변수로 하는 2차식이 남는다. 대규모 T에서는 상수항을 무시하고, y_T 에 대한 convex quadratic 문제로 단순화된다. 이를 최소화하기 위해 두 가지 알고리즘을 제시한다.
1. **비동기(좌표 하강) 알고리즘**
- 각 출력 차원을 순차적으로 최적화한다.
- 최적화 식을 전개하면 y_T,i = Σ_j W_{ij} x_T,j – Σ_{j≠i} M_{ij} y_T,j 형태가 된다.
- 여기서 W_{ij}= (1/T) Σ_t y_{t,i} x_{t,j} / D_{T,i}, M_{ij}= (1/T) Σ_t y_{t,i} y_{t,j} / D_{T,i} (i≠j)이며, D_{T,i}= Σ_t y_{t,i}² 은 누적 활성도이다.
- 학습 규칙은
ΔW_{ij}= y_T,i (x_T,j – W_{ij} y_T,i)/D_{T+1,i} (Hebbian)
ΔM_{ij}= y_T,i (y_T,j – M_{ij} y_T,i)/D_{T+1,i} (anti‑Hebbian)
로, 완전히 로컬이며 학습률은 D_{T+1,i}⁻¹ 로 자동 조정된다.
2. **동기(Jacobi) 알고리즘**
- 좌표 하강 대신 Jacobi 반복을 사용해 y_T ← W x_T – M y_T 를 동시에 업데이트한다.
- 수렴 조건은 M의 스펙트럼 반경이 1보다 작아야 하지만, 실제 시뮬레이션에서는 대부분 만족한다.
- 가중치 업데이트는 비동기와 동일한 로컬 규칙을 사용한다.
두 알고리즘 모두 동일한 고정점을 갖는다. 고정점 분석을 통해, WᵀW = I_m, M = D⁻¹R (R은 비대각 성분)이며, 최종 출력 y_T = (I+M)⁻¹ W x_T 가 된다. 대규모 T에서 M은 작아져 (I+M)⁻¹ ≈ I 가 되고, y_T ≈ W x_T 가 된다. W는 입력 공분산 행렬 C의 상위 m개의 고유벡터를 열로 갖는 직교 행렬이므로, 네트워크는 정확히 주성분 서브스페이스를 구현한다.
안정성 분석에서는 고정점이 안정하려면 해당 서브스페이스가 C의 상위 m 고유값에 대응해야 함을 증명한다. 또한, 비정상적인 데이터 흐름(시간에 따라 평균·공분산이 변하는 경우)에서는 지수적 평균을 적용해 D_{T,i} 를 최신 데이터에 가중치를 높게 두도록 하면, 네트워크가 서브스페이스를 실시간으로 추적한다는 것을 실험적으로 확인하였다.
실험에서는 합성 Gaussian 데이터와 MNIST 이미지 스트림을 사용해 기존 GHA, Oja‑based 다중 뉴런 네트워크와 비교하였다. 제안된 알고리즘은 수렴 속도가 2~3배 빠르고, 최종 재구성 오차가 더 낮았다. 특히 비동기 버전은 거의 항상 수렴을 보였으며, 동기 버전은 병렬 구현 시 연산 효율이 크게 향상된다.
결론적으로, 이 논문은 CMDS 비용 함수를 온라인으로 최소화함으로써, 완전 로컬 Hebbian/anti‑Hebbian 학습 규칙만으로도 주성분 서브스페이스를 정확히 학습할 수 있음을 보였다. 이는 생물학적 신경 회로 모델링과 현대 머신러닝 양쪽 모두에 중요한 통합 프레임워크를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기