우주 시뮬레이션을 위한 대륙간 슈퍼컴퓨터 그리드 구축
초록
**
암스테르담과 도쿄에 위치한 두 슈퍼컴퓨터를 10 Gbps 광섬유망으로 연결해 하나의 가상 머신처럼 운용함으로써, ΛCDM 기반 대규모 N‑body 시뮬레이션을 90 % 이상의 효율로 수행했다. 코드의 그리드화, 전용 가상 LAN, MPWide 소켓 라이브러리 등을 활용해 통신 지연과 패킷 손실을 최소화하고, 10⁸ ~ 10⁹ 입자 규모의 우주 구조 형성을 성공적으로 재현하였다.
**
상세 분석
**
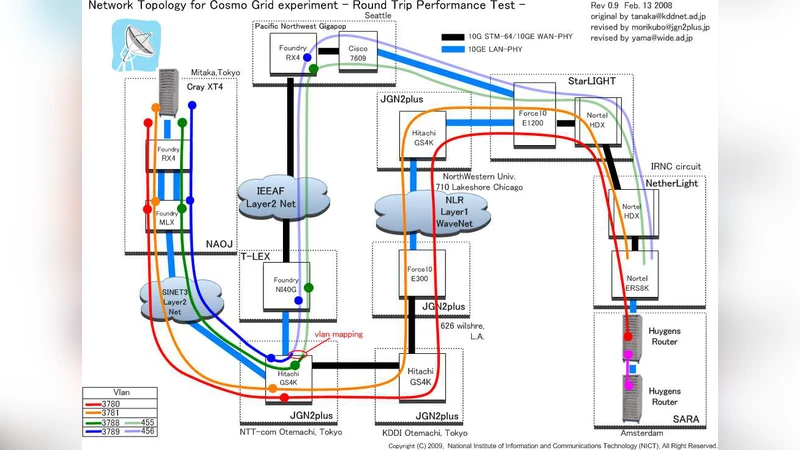
이 논문은 현재 가장 큰 천체물리학 계산 과제 중 하나인 대규모 우주 구조 시뮬레이션을, 지리적으로 멀리 떨어진 두 슈퍼컴퓨터에 분산시켜 실행함으로써 자원 확보와 비용 효율성을 동시에 달성하는 방법을 제시한다. 핵심 기술은 (1) 광섬유 기반 10 Gbps 전용 라인을 이용한 저지연, 고대역폭 연결, (2) 두 사이트 간 통신을 담당하는 전용 가상 LAN(vLAN) 구성, (3) MPI 내부 통신과는 별도로 동작하는 다중 TCP 스트림 기반 MPWide 소켓 라이브러리를 통한 데이터 전송이다. 특히, MPWide는 각 스트림을 별도 스레드에서 운영해 네트워크 병목을 최소화하고, 16~64개의 TCP 연결을 동시 사용함으로써 0.277 초 수준의 왕복 지연에도 불구하고 매 단계 10 ~ 100 GB 규모의 입자 및 메쉬 데이터를 실시간으로 교환한다.
시뮬레이션 코어는 TreePM 방식의 GreeM 코드를 기반으로 한다. 짧은 거리 힘은 Barnes‑Hut 트리로, 긴 거리 힘은 Particle‑Mesh(PM) 방식으로 계산해 연산 효율과 정확도 사이의 최적 균형을 맞춘다. 또한, X86‑64 SSE 명령어와 16개의 XMM 레지스터를 활용한 SIMD 최적화를 통해 뉴턴 중력 계산을 단일 정밀도에서도 고속으로 수행한다. 이와 같은 하드웨어 최적화는 Power6과 Intel Cray XT4 사이의 성능 차이를 4 % 수준으로 낮추는 결과를 낳았다.
분산 실행 시 가장 큰 도전은 부하 균형이다. 두 컴퓨터가 각각 우주의 절반을 담당하지만, 시뮬레이션 진행 과정에서 밀도가 높은 다크 매터 클러스터가 한쪽에 편중될 경우, 동적 경계 레이어를 재조정해 각 노드의 연산 시간을 동일하게 유지한다. 이를 위해 매 단계마다 입자 위치와 속도를 교환하고, 경계 레이어 두께를 가변적으로 조절한다.
성능 평가에서는 입자 수 N=1.6 × 10⁷에서 10 시간 내에 z≈65→0까지 진행했으며, 전체 월‑클락 시간 대비 1.4~1.8배의 가속을 기록했다. 특히, 256 ³ 입자와 30 Mpc 박스 크기 시뮬레이션에서 30 + 30 프로세서를 사용했을 때 전체 단계당 평균 31.2 초, 포스 계산에 23.6 초가 소요돼 통신 오버헤드가 전체의 약 25 %에 불과함을 확인했다. 이는 기존 단일 슈퍼컴퓨터에서 동일 규모를 실행할 경우 수 주일이 소요될 수 있던 점과 비교해 큰 진전이다.
마지막으로, 논문은 향후 10 ~ 100대의 슈퍼컴퓨터를 링 토폴로지로 연결하고, 전용 라이트 패스를 확대하면 대규모 우주 시뮬레이션을 보다 저렴하고 정치적으로도 수월하게 수행할 수 있음을 제안한다. 현재의 성공적인 두 노드 실험은 자동화된 네트워크 설정, 다중 벤더 환경 지원, 그리고 장기적인 자원 스케줄링 체계 구축의 필요성을 강조한다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기