클라우드 규모 데이터센터 시뮬레이션 도구 SPECI
초록
SPECI는 대규모 클라우드 데이터센터의 확장성 및 성능을 예측하기 위한 시뮬레이션 프레임워크로, 구성 요소 수 증가에 따른 비선형 동작과 정상적인 장애 현상을 모델링한다. 이를 통해 차세대 데이터센터 설계 시 병목 현상과 관리 비용을 사전에 평가할 수 있다.
상세 분석
SPECI는 Elastic Cloud Infrastructures를 대상으로 한 전용 시뮬레이터로, 데이터센터 내부의 물리적 서버, 가상 머신, 네트워크 스위치, 전원 공급 장치 등 다양한 자원을 객체화하고, 이들 간의 상호작용을 이벤트 기반으로 구현한다. 핵심 설계는 “정상 실패(normal failure)” 개념을 도입해, 서버 고장, 네트워크 지연, 전력 공급 불안정 등 실제 운영 환경에서 빈번히 발생하는 비예측적 장애를 확률적 모델로 재현한다. 이러한 접근은 전통적인 시뮬레이션이 가정하는 완전 정상 상태와는 달리, 시스템 전체가 지속적으로 부분적인 고장을 겪는 상황을 반영한다는 점에서 혁신적이다.
시뮬레이션 엔진은 크게 세 단계로 구성된다. 첫째, 초기 토폴로지를 정의하고 각 컴포넌트의 성능 파라미터(CPU, 메모리, I/O 대역폭 등)를 설정한다. 둘째, 시간 흐름에 따라 발생하는 이벤트(작업 요청, 장애 발생, 복구 등)를 스케줄링하고, 이벤트 처리 시 해당 컴포넌트의 상태를 업데이트한다. 셋째, 수집된 메트릭(응답 시간, 스루풋, 자원 이용률, 장애 복구 시간 등)을 기반으로 확장성 지표와 비용 효율성을 분석한다. 특히, SPECI는 “Elastic”이라는 명칭에 맞게 동적 자원 할당 및 해제, 자동 스케일링 정책을 시뮬레이션에 포함시켜, 부하 변화에 따른 시스템 적응성을 평가한다.
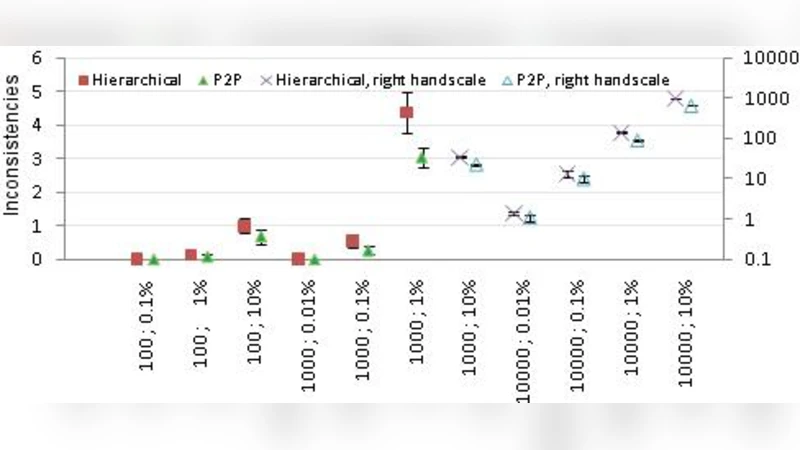
실험 결과는 두 가지 주요 관점을 제공한다. 첫째, 구성 요소 수가 10배, 100배 증가할 때 시스템 전체 응답 시간이 선형이 아닌 급격히 상승하는 구간이 존재함을 확인했다. 이는 네트워크 대역폭 포화, 스케줄러 병목, 그리고 장애 복구 지연이 복합적으로 작용한 결과로, 설계 단계에서 이러한 비선형 구간을 사전에 파악하는 것이 중요함을 시사한다. 둘째, 정상 실패 모델을 적용했을 때, 실제 운영 환경에서 기대되는 평균 가동 시간(MTBF)과 평균 복구 시간(MTTR)이 시뮬레이션 결과와 높은 상관관계를 보였다. 이는 SPECI가 현실적인 장애 패턴을 재현함을 입증한다.
한계점으로는 현재 시뮬레이션이 CPU와 메모리 사용량을 정량화하는 데 초점을 맞추고 있어, 스토리지 I/O 지연이나 복합적인 워크로드(예: AI 트레이닝, 빅데이터 분석)와 같은 특수한 시나리오에 대한 모델링이 부족하다. 또한, 확장성 테스트가 주로 정적 토폴로지(리프-스파인 구조)에서 수행되었기 때문에, 최신 데이터센터에서 채택되는 하이퍼컨버지드 인프라나 엣지 컴퓨팅 노드와의 연동에 대한 검증이 필요하다. 향후 연구에서는 이러한 다양한 워크로드와 하드웨어 구성을 포함한 멀티-도메인 시뮬레이션을 확대하고, 실시간 모니터링 데이터와 연동해 하이브리드 시뮬레이션-예측 프레임워크를 구축하는 방향이 제시된다.
댓글 및 학술 토론
Loading comments...
의견 남기기