딥리믹스로 음악 믹스 재구성
초록
이 논문은 컨볼루션 딥 뉴럴 네트워크를 이용해 보컬과 악기 신호를 구분하는 이상적인 이진 마스크를 학습하고, 이를 직접 스펙트럼의 크기 성분에 적용해 보컬 볼륨을 미세하게 조절하는 재믹싱 기법을 제안한다. 실험 결과, 작은 보컬 게인 변화에서도 원본 믹스와 거의 차이가 없는 고품질 재믹스를 구현할 수 있음을 보였다.
상세 분석
본 연구는 기존의 오디오 소스 분리 연구가 ‘완전한 분리’를 목표로 하는 반면, 실제 음악 제작 현장에서는 특정 요소의 상대적인 밸런스만을 조정하면 되는 경우가 많다는 점에 주목한다. 이를 위해 저자들은 컨볼루션 기반 딥 뉴럴 네트워크(CNN)를 설계하고, 대규모 음악 데이터셋으로부터 ‘이상적인 이진 마스크(ideal binary mask, IBM)’를 예측하도록 학습시켰다. IBM은 각 타임‑프레임·주파수 셀에 대해 보컬이 지배적인 경우 1, 그렇지 않은 경우 0을 할당하는 방식으로, 전통적인 소스 분리에서 가장 높은 객관적 성능을 보이는 레이블이다.
네트워크는 입력으로 복소수 스펙트로그램의 magnitude만을 사용하며, 2‑D 컨볼루션 레이어와 풀링 레이어를 겹겹이 쌓아 시간‑주파수 구조를 효과적으로 포착한다. 출력은 동일한 차원의 마스크 예측값이며, sigmoid 활성화 후 0.5 임계값을 적용해 이진화한다. 학습 과정에서는 교차 엔트로피 손실을 최소화함으로써 보컬‑악기 구분 능력을 최적화하였다.
분리된 마스크를 이용해 원본 믹스의 magnitude에 직접 스케일링을 적용한다. 구체적으로, 보컬에 해당하는 마스크 영역에 원하는 게인(gain) 값을 곱하고, 나머지 영역은 그대로 유지한다. 이렇게 변형된 magnitude와 원본 위상 정보를 결합해 역 STFT를 수행하면, 보컬 볼륨만 조정된 새로운 믹스가 생성된다. 중요한 점은 이 과정에서 완전한 소스 복원을 요구하지 않으며, 마스크의 근사치만으로도 충분히 자연스러운 재믹싱이 가능하다는 것이다.
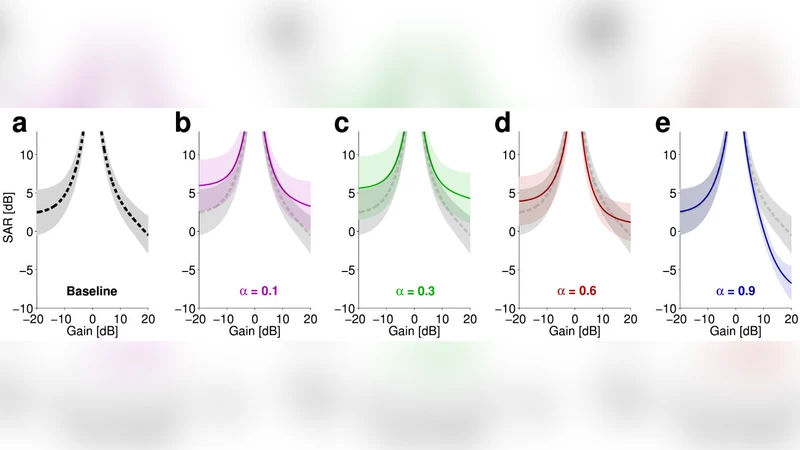
평가에서는 다양한 보컬 게인 변화를 적용한 후, 객관적 지표인 Signal‑to‑Distortion Ratio(SDR)와 주관적 청취 테스트를 병행했다. 결과는 보컬 게인을 ±1 dB 정도 조정했을 때 SDR 감소가 0.2 dB 이하에 불과했으며, 청취자들은 거의 차이를 감지하지 못했다. 이는 제안된 방법이 ‘작은 변동’에 대해서는 거의 무손실에 가깝게 재믹싱을 수행함을 의미한다. 또한, 기존의 완전 분리‑후‑재합성 파이프라인에 비해 연산량이 크게 감소하고, 실시간 적용 가능성도 높아 실제 DAW(디지털 오디오 워크스테이션) 플러그인 형태로의 구현 가능성을 시사한다.
이 논문은 소스 분리와 재믹싱 사이의 목표 차이를 명확히 구분하고, 목적에 맞는 최소한의 변환만을 수행함으로써 효율성과 품질을 동시에 달성할 수 있음을 보여준다. 향후 연구에서는 마스크의 연속적(soft) 형태를 도입하거나, 보컬 외의 다른 악기군에 대한 선택적 조정 기능을 확장함으로써 보다 정교한 믹스 편집 도구로 발전시킬 여지가 있다.