일반화된 리비키‑프레스 알고리즘: 반분리 행렬의 O(N) 직접 해법 및 행렬식 계산
본 논문은 지수 합 형태의 공분산 행렬(반분리 행렬)을 대상으로, 새로운 변수 도입으로 행렬을 넓은 밴드 형태로 변환하고, 기존의 밴드 LU 알고리즘을 이용해 O(N) 시간에 선형 시스템을 풀고 행렬식을 구하는 일반화된 리비키‑프레스 알고리즘을 제안한다. 수치적 안정성을 확보하기 위한 전처리와 구현 상세, 그리고 선형 스케일링을 확인한 벤치마크 결과를 제공한다.
저자: Sivaram Ambikasaran
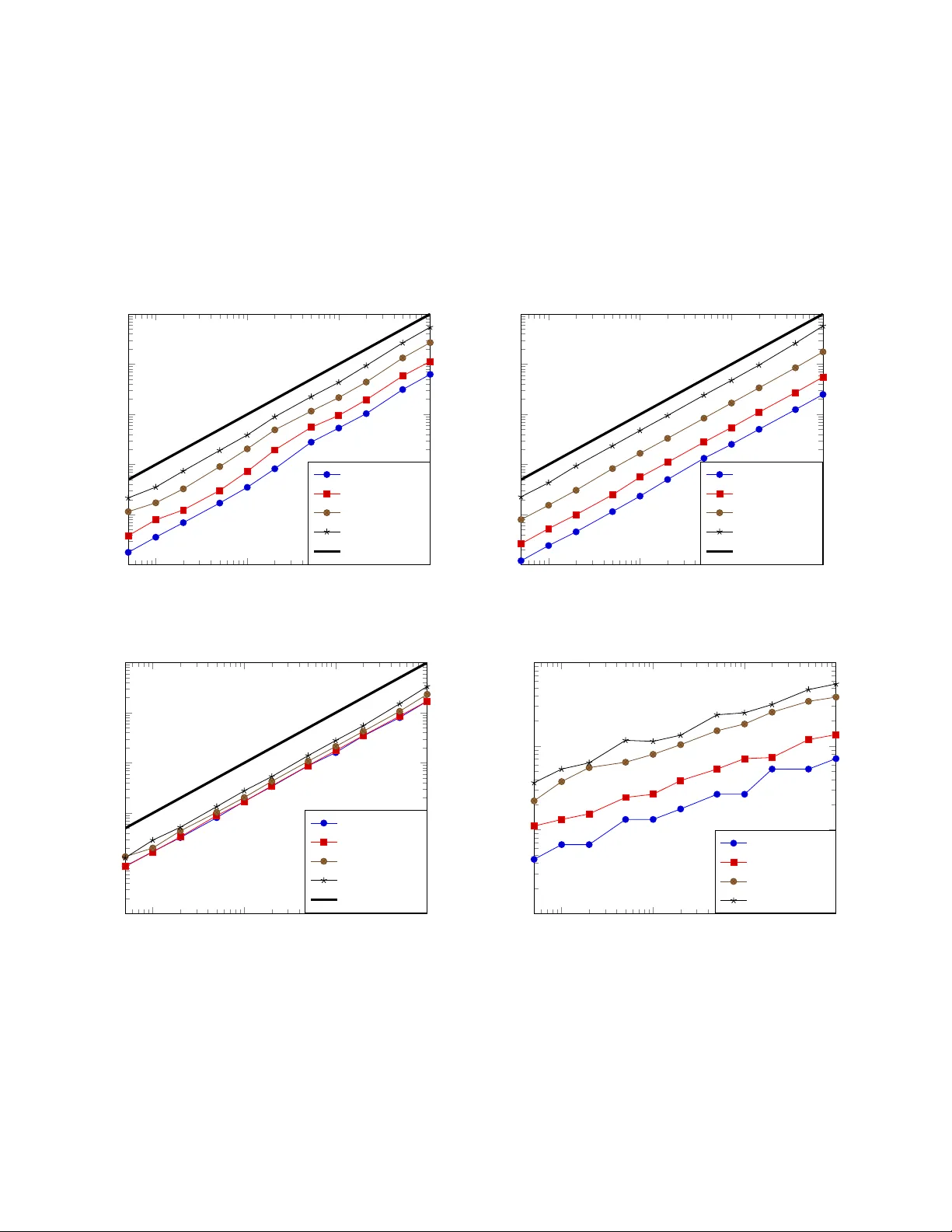
본 논문은 대규모 시계열 및 통계 모델링에서 자주 등장하는 “지수 합 형태”의 공분산 행렬을 효율적으로 다루기 위한 새로운 알고리즘을 제시한다. 저자는 먼저 반분리(semi‑separable) 행렬을 정의하고, 그 구조가 A = D + triu(B_p) + tril(C_p) 형태로 표현될 수 있음을 설명한다. 여기서 D는 대각 행렬, B_p와 C_p는 반분리 랭크 p인 상삼각·하삼각 행렬이다. 기존 연구에서는 O(N p²) 혹은 O(N log N) 복잡도의 알고리즘이 제안되었지만, 수치적 불안정성이나 구현 복잡도가 문제점으로 지적되었다.
저자는 새로운 접근법으로, 원래의 N×N 반분리 행렬을 (2p+1)N‑2p 차원의 희소 밴드 행렬 A_ex 로 확장한다. 이를 위해 각 행에 대해 보조 변수 r_k^{(p)}와 l_k^{(p)}(벡터 길이 p)를 도입한다. 구체적으로, r_k^{(p)} = V_k^T x_k + r_{k+1}^{(p)}, l_k^{(p)} = U_k^T x_k + l_{k-1}^{(p)} (k=2,…,N‑1) 로 정의하고, 경계 조건 r_N^{(p)} = V_N^T x_N, l_1^{(p)} = U_1^T x_1을 설정한다. 이렇게 하면 원래의 선형 시스템 Ax = b 가 3N‑2(또는 (2p+1)N‑2p) 개의 방정식으로 변환되고, 이 방정식들은 모두 대각선에 인접한 2p+1개의 비제로 원소만을 갖는 밴드 구조를 형성한다.
다음으로, 저자는 이 확장된 행렬의 행렬식이 원 행렬 A의 행렬식과 부호만 차이 나는 동일함을 증명한다. A_ex을 적절히 행·열 순열(P₁, P₂)한 뒤, L_Δ·U_Δ·D 형태의 블록 행렬로 분해하고, L_Δ와 U_Δ는 대각이 1인 삼각 행렬이므로 det(L_Δ)=det(U_Δ)=1이다. 블록 행렬식 전개를 이용하면 Schur 보완이 정확히 A와 일치함을 보이며, 따라서 det(A_ex)=±det(A)임을 얻는다. 이 결과는 행렬식 계산을 위해 별도의 복잡한 연산이 필요 없으며, 단순히 A_ex에 대한 LU 분해만 수행하면 된다.
수치적 안정성을 확보하기 위해, 지수 함수의 급격한 스케일 차이를 직접 보정한다. 예를 들어, 전통적인 Rybicki‑Press 알고리즘은 A(i,j)=exp(−β|t_i−t_j|) 형태의 행렬에 대해 u_i=exp(β t_i), v_i=exp(−β t_i) 로 분해하지만, t_i가 넓은 구간에 걸리면 u_i·v_i가 언더플로우·오버플로우를 일으킨다. 저자는 r_k, l_k 정의에 exp(−βΔt) 계수를 포함시켜 스케일을 정규화하고, 이를 일반화된 CARMA(p,q) 공분산 K(r)=d + ∑_{l=1}^p α_l exp(−β_l r) 에도 적용한다. α와 γ(Δt) 벡터를 이용해 r_k = α x_k + D(k,k+1) r_{k+1}, l_k = γ_{k‑1} x_{k‑1} + D(k‑1,k) l_{k‑1} 로 재정의함으로써, 모든 연산이 안정적인 수치 범위 내에서 수행된다.
알고리즘 구현은 C++와 Eigen 라이브러리를 사용했으며, SparseLU(슈퍼LU 기반)와 COLAMD 사전 순서를 적용해 실제 밴드 구조를 유지한다. 실험에서는 N을 500부터 5000까지, 반분리 랭크 p를 1, 5, 10 등으로 변동시켰다. 결과는 다음과 같다. (1) 조립, 분해, 해석 단계 모두 O(N) 시간에 수행되었으며, 특히 대규모 N에서 기존 dense LU(PartialPivLU) 대비 10배 이상 빠른 속도를 보였다. (2) 잔차 ‖Ax−b‖_∞는 10⁻¹⁴ 수준으로, 기계 정밀도에 근접한 정확도를 유지했다. (3) 로그 행렬식 차이 |log|A_ex|−log|A||도 10⁻¹⁴ 이하로 매우 작았다. (4) 메모리 사용량도 O(pN) 수준으로, dense N² 메모리 요구와 비교해 크게 절감되었다.
결론적으로, 논문은 반분리 행렬을 밴드 형태로 확장하는 일반적인 프레임워크와, 그에 기반한 O(N) 직접 해법 및 행렬식 계산 방법을 제시한다. 이 방법은 수치적 안정성을 보장하면서도 기존의 복잡한 알고리즘보다 구현이 간단하고, 기존의 고성능 희소 선형 대수 라이브러리를 그대로 활용할 수 있다는 실용적 장점을 가진다. 특히, 반분리 랭크 p가 상수(보통 1~5)인 경우, 대규모 시계열 분석, Gaussian Process 회귀, CARMA 모델 추정 등에서 메모리와 시간 효율을 크게 개선할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기