텍스트에서 의미 표현을 유도하는 공동 예측과 인수 분해 모델
초록
본 논문은 의미역 라벨링을 위한 인코더와 인수 예측을 위한 텐서 인수분해 재구성 모델을 동시에 학습함으로써, 사전 언어 지식 없이도 영어 코퍼스에서 인간이 정의한 의미역과 유사한 역할을 자동으로 유도한다. 재구성 오류를 최소화하는 목표함수를 이용해 두 구성요소를 공동 최적화하고, 실험 결과 기존 최첨단 비지도 SRL 방법들과 동등하거나 우수한 성능을 달성하였다.
상세 분석
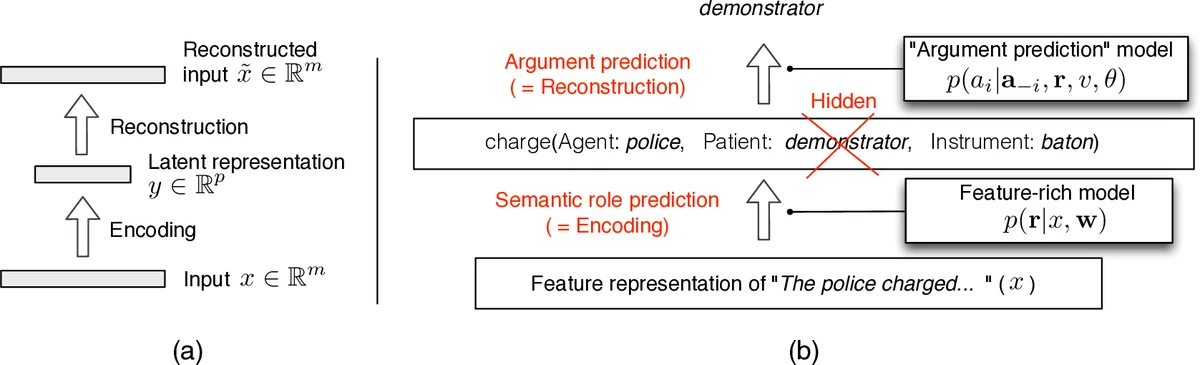
이 연구는 의미역 라벨링(semantic role labeling, SRL) 문제를 두 단계의 확률 모델로 분해한다. 첫 번째는 풍부한 구문·어휘 특징을 이용해 역할을 예측하는 로그선형 인코더이며, 두 번째는 역할과 술어를 조건으로 인수를 재구성하는 텐서‑베이스의 bilinear softmax 모델이다. 인코더는 p(r|x,w)∝exp(wᵀg(x,r)) 형태의 조건부 확률을 정의하고, g(x,r)는 논문에서 49,474개의 이산 특징을 포함한다. 재구성 모델은 각 인수 a_i를 다른 인수와 역할, 술어 v에 의해 결정되는 확률 p(a_i|a_{-i},r,v,C,u)=exp(u_a_iᵀ C_{v,r_i}ᵀ C_{v,r_j} u_{a_j})/Z 로 표현한다. 여기서 u_a∈ℝ^d는 인수 임베딩, C_{v,r}∈ℝ^{d×k}는 술어‑역별 투사 행렬이며, Z는 전체 어휘에 대한 정규화 상수다. 이 구조는 인수 간 의미적 호환성을 내재화하고, 역할이 인수 예측을 단순화하도록 유도한다.
학습 목표는 전체 코퍼스에 대해 Σ_i log Σ_r p(a_i|a_{-i},r,v,C,u)·p(r|x,w) 를 최대화하는 것이지만, 직접 최적화는 (1) 역할 변수 r에 대한 지수적 합산, (2) Z의 전 어휘 합산 때문에 비현실적이다. 이를 해결하기 위해 저자는 평균장(mean‑field) 근사를 도입해 p(r|x,w)의 후방분포 μ_i^s를 사용하고, Z 계산은 네거티브 샘플링(negative sampling)으로 근사한다. 최적화는 AdaGrad와 무작위 초기화를 통해 수행된다.
실험에서는 CoNLL‑2008 영어 데이터셋을 사용해 무감독 SRL 성능을 평가했으며, 순도(purity), 결합도(collocation), F1을 주요 지표로 삼았다. 제안 모델은 4~6개의 역할만을 학습했음에도 불구하고, 기존 베이즈 기반 모델이 30개 이상 역할을 생성하는 경우와 비교해 인간이 해석하기 쉬운 역할 구성을 제공한다. 특히, 역할 간 구분이 명확해 에이전트와 페이션트가 잘 식별된다.
이 논문의 핵심 기여는 (1) 재구성 오류 최소화를 통한 로그선형 인코더와 텐서 인수분해 재구성기의 공동 학습 프레임워크 제시, (2) 풍부한 특징을 활용하면서도 언어‑특정 사전 지식에 의존하지 않는 완전 비지도 학습 방식 구현, (3) 실험적으로 기존 최첨단 비지도 SRL 방법들과 동등하거나 우수한 성능을 입증한 점이다. 또한, 텐서 인수분해와 자동 인코더 개념을 의미론적 역할 학습에 적용함으로써, 의미론적 구조와 분산 표현 사이의 연결 고리를 제공한다는 점에서 이론적·실용적 의의가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기