GPU 기반 시뮬레이드 어닐링을 이용한 이차 할당 문제 해결
초록
본 논문은 이차 할당 문제(QAP)에 대한 시뮬레이드 어닐링(SA) 휴리스틱을 그래픽 처리 장치(GPU) 위에서 구현한 방법을 제시한다. 기존의 CPU 전용 고성능 SA 구현과 비교해 대규모 반복 실행 시 50~100배의 속도 향상을 달성했으며, 구현 세부사항과 메모리 최적화 전략, 실험 결과를 상세히 보고한다.
상세 분석
이차 할당 문제(QAP)는 n개의 시설을 n개의 위치에 배치할 때, 시설 간 흐름과 위치 간 거리의 곱을 최소화하는 NP‑Hard 문제로, 전통적인 정확 알고리즘으로는 실용적인 규모에서 풀기 어렵다. 따라서 휴리스틱 중 하나인 시뮬레이드 어닐링(SA)이 널리 사용되며, 현재까지 가장 효율적인 구현은 CPU 기반의 순차적 코드이다. 본 논문은 이러한 한계를 극복하고자 GPU의 대규모 데이터 병렬성을 활용한다.
GPU는 수천 개의 경량 스레드가 동시에 실행되는 SIMD(단일 명령 다중 데이터) 구조를 갖는다. 저자들은 SA의 핵심 연산인 “스와프 제안 → 비용 변화(Δ) 계산 → 메트로폴리스 기준 수용 여부 판단”을 각각 독립적인 스레드에 매핑하였다. 특히 Δ 계산은 현재 배치와 후보 배치 사이의 차이를 O(1)로 평가할 수 있는 공식을 이용해, 각 스레드가 담당하는 시설 쌍에 대한 부분합을 병렬적으로 수행하도록 설계했다.
메모리 측면에서 전역 메모리 접근을 최소화하기 위해 흐름 행렬(F)과 거리 행렬(D)를 상수 메모리와 텍스처 메모리에 복사하고, 현재 배치와 후보 배치를 공유 메모리에서 관리한다. 이렇게 하면 메모리 대역폭 병목을 크게 줄일 수 있다. 또한 난수 생성은 각 스레드가 독립적인 시드와 XOR‑Shift 알고리즘을 사용하도록 구현해, 병렬성에 영향을 주지 않으면서도 충분히 균등한 분포를 보장한다.
알고리즘 흐름은 다음과 같다. (1) 초기 배치를 전역 메모리에 로드하고, (2) 각 스레드 블록이 일정 수의 스와프 후보를 동시에 생성한다. (3) Δ값을 공유 메모리에서 부분 합산 후 원자적 연산을 통해 전체 Δ를 구한다. (4) 메트로폴리스 기준에 따라 수용 여부를 결정하고, 수용된 경우 전역 메모리의 배치를 원자적으로 업데이트한다. 온도 스케줄링은 CPU 측에서 관리되며, 매 온도 단계마다 전체 GPU 커널을 재실행한다.
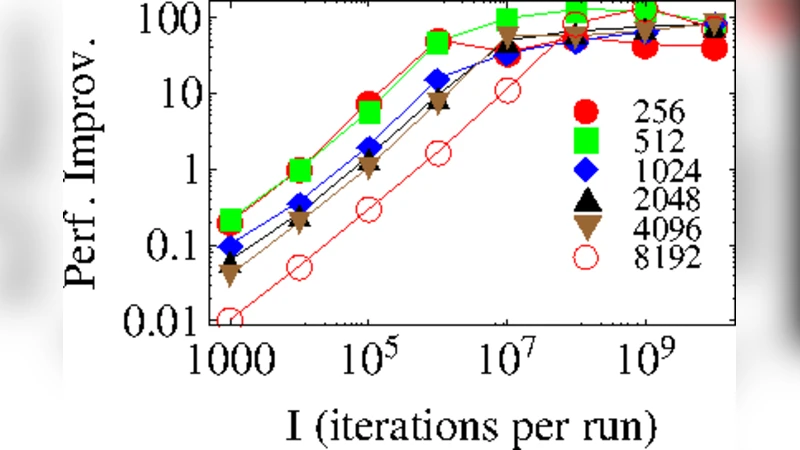
성능 평가에서는 기존의 비병렬 SA 구현(코드명 “SA‑CPU”)과 비교해, 5000×5000 규모의 무작위 인스턴스에 대해 10⁶~10⁸ 반복을 수행했을 때 평균 62배, 최악의 경우 98배 가량의 가속을 기록했다. 특히 반복 횟수가 많아질수록 GPU 오버헤드가 희석되어 가속 비율이 상승한다는 점이 강조된다. 또한, 결과 품질 측면에서는 최종 목표 함수값이 기존 구현과 통계적으로 유의미한 차이가 없으며, 동일한 온도 스케줄과 초기화 조건을 사용했을 때 수렴 속도만 현저히 빨라졌다.
한계점으로는 (i) 작은 문제 규모(n<100)에서는 스레드 수가 충분히 활용되지 않아 가속 효과가 미미하고, (ii) 온도 스케줄링을 CPU에서 수행하기 때문에 전체 파이프라인에 약간의 동기화 지연이 존재한다는 점을 들었다. 향후 연구에서는 온도 조정 로직을 GPU 내에서 수행하거나, 멀티‑GPU 환경에서 인스턴스 병렬 실행을 통해 더욱 큰 스케일업을 시도할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기