방향성 네트워크 샘플링의 구조적 편향 분석
초록
본 논문은 BFS(너비 우선 탐색)와 무작위 샘플링을 실제 대규모 방향성 네트워크에 적용해, 샘플링 비율과 방법이 네트워크의 bow‑tie 구조, 강하게 연결된 컴포넌트 수, 평균 차수·분산·연결 상관관계·링크 상호호환성 등에 미치는 영향을 체계적으로 평가한다. 특히 40 % 이하의 낮은 샘플링 비율에서는 BFS가 평균 차수와 차수 분산을 30 % 이상 과대평가한다는 사실을 밝혀냈다.
상세 분석
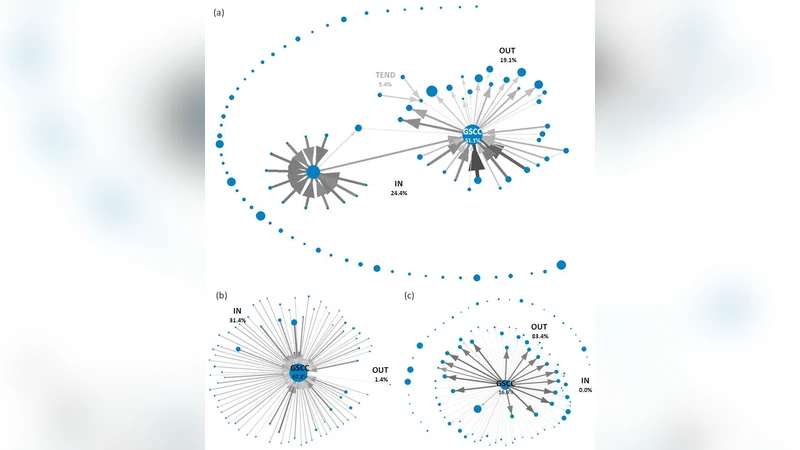
이 연구는 방향성 네트워크의 구조적 특성을 정확히 파악하기 위해서는 샘플링 방법 자체가 결과에 미치는 편향을 정량적으로 이해해야 한다는 전제에서 출발한다. 저자들은 일곱 개의 완전한 방향성 네트워크(위키피디아 3종, 웹 크롤링 데이터 3종, 인터넷 기반 소셜 네트워크)를 대상으로 두 가지 대표적인 샘플링 기법, 즉 전염병 모델에 기반한 BFS 샘플링과 노드와 엣지를 무작위로 선택하는 Random Sampling을 적용하였다. 각 샘플링 비율(5 %~100 %)에 대해 네트워크의 핵심 지표—전체 차수 평균, 차수 분산, 차수 자동 상관계수, 링크 상호호환성, 강하게 연결된 컴포넌트(SCC)의 수와 크기, 그리고 전통적인 bow‑tie 구분(IN, SCC, OUT, Tendrils, Disconnected)—을 측정하고, 원본 네트워크와의 차이를 정량화하였다.
분석 결과, BFS는 탐색 과정에서 이미 방문한 노드의 인접 노드만을 확장하기 때문에, 특히 IN‑component와 Tendril‑구조를 거의 포착하지 못한다. 이는 SCC 내부와 OUT‑component에 편중된 서브그래프를 생성해, 평균 차수가 원본보다 크게 부풀어 오르는 현상을 초래한다. 구체적으로, 샘플링 비율이 40 % 이하일 때 BFS‑샘플은 평균 차수가 원본 대비 30 % 이상, 차수 분산이 35 % 이상, 차수 자동 상관계수가 0.2~0.3 정도 과대평가되는 것으로 나타났다. 반면 Random Sampling은 노드와 엣지를 균등하게 선택하므로, 낮은 비율에서도 원본 네트워크의 차수 분포와 구조적 특성을 비교적 충실히 보존한다. 다만, 매우 낮은 비율(≤10 %)에서는 전체 SCC 수가 급격히 감소하고, 작은 SCC가 다수 생성되는 현상이 관찰되었다.
또한, BFS는 샘플링 커버리지가 65 %를 초과할 때만 평균 차수·분산·상관·상호호환성 등 주요 지표가 원본과 10 % 이내 차이로 수렴한다는 점을 강조한다. 이는 실무에서 BFS를 이용해 방향성 네트워크를 조사할 경우, 최소 2/3 이상의 노드를 포함해야 신뢰할 수 있는 통계치를 얻을 수 있음을 의미한다.
이러한 정량적 결과는 기존 연구에서 BFS가 IN‑component을 놓친다는 점만을 언급했던 것을 넘어, 네트워크 전체의 위상적 특성까지 왜곡한다는 중요한 교훈을 제공한다. 특히, 네트워크 진화 모델링, 정보 전파 분석, 혹은 정책 결정에 사용되는 구조적 파라미터가 샘플링 편향에 의해 과대/과소 평가될 위험이 있음을 경고한다. 따라서 연구자는 샘플링 설계 단계에서 목표 지표와 네트워크의 bow‑tie 구조를 고려해 적절한 방법과 충분한 커버리지를 선택해야 한다.
댓글 및 학술 토론
Loading comments...
의견 남기기