한 번에 최적화하는 결합 행렬·텐서 분해 기법
초록
본 논문은 행렬과 고차원 텐서를 동시에 분석하는 결합 행렬·텐서 분해(CMTF) 문제를 기존의 교대형 ALS 방식이 아닌, 모든 변수들을 한 번에 최적화하는 gradient‑based 알고리즘 CMTF‑OPT으로 해결한다. 결측값을 포함한 불완전 데이터에도 적용 가능하도록 확장했으며, 실험을 통해 CMTF‑OPT가 정확도와 수렴 속도 면에서 ALS보다 우수함을 입증한다.
상세 분석
본 연구는 데이터 융합 분야에서 행렬과 텐서라는 이질적인 구조를 동시에 다루는 결합 행렬·텐서 분해(CMTF) 문제를 새롭게 접근한다. 전통적으로 CMTF는 각 모드별(행렬·텐서) 요인 행렬을 교대로 업데이트하는 ALS(Alternating Least Squares) 방식에 의존했으며, 이는 컴포넌트 수가 잘못 추정되었을 때 수렴이 느리거나 지역 최적점에 머무를 위험이 있었다. 논문은 이러한 한계를 극복하기 위해 모든 요인 행렬 A, B, C, V를 동시에 최적화하는 일괄(ALL‑AT‑ONCE) 방법인 CMTF‑OPT을 제안한다. 핵심 아이디어는 목적함수
(f(A,B,C,V)=|X-\llbracket A,B,C\rrbracket|_F^2+|Y-AV^{\top}|_F^2)
에 대해 직접적인 그래디언트를 계산하고, L‑BFGS 혹은 비선형 CG와 같은 1차 최적화 기법을 적용하는 것이다. 이때 텐서의 CP 모델을 행렬 형태로 전개하여 Khatri‑Rao 곱을 이용해 그래디언트를 효율적으로 구한다. 또한, 결측값을 마스크 행렬 W로 표시하고 손실함수에 (1‑W)⊙(·) 연산을 삽입함으로써 불완전 데이터에 대한 확장도 자연스럽게 수행한다.
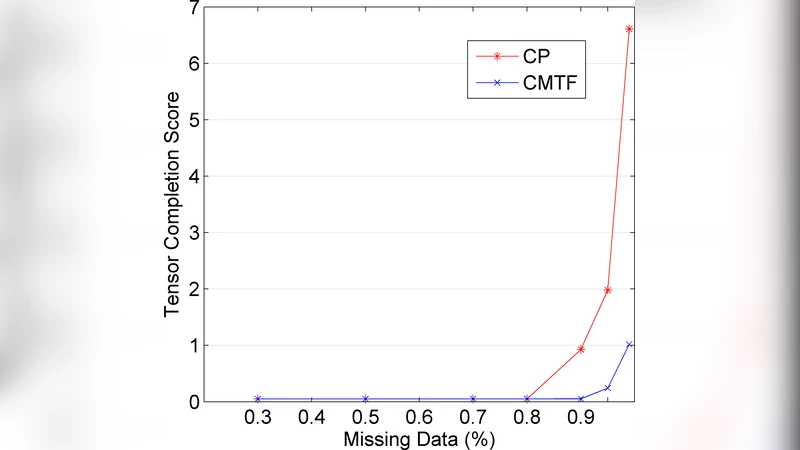
알고리즘 설계 측면에서 중요한 점은 (i) 파라미터 스케일링을 위해 각 요인 행렬을 정규화하고, (ii) 라인 서치 단계에서 Wolfe 조건을 만족하도록 단계 크기를 조정함으로써 수치적 안정성을 확보한다는 것이다. 실험에서는 합성 데이터와 실제 레스토랑 평점·소셜 네트워크·카테고리 매트릭스(3‑order 텐서 + 2‑order 매트릭스) 를 사용해 CMTF‑OPT와 기존 CMTF‑ALS를 비교하였다. 결과는 (1) 동일한 초기값에서 CMTF‑OPT이 더 낮은 최종 손실값을 달성하고, (2) 특히 80 % 이상 결측이 존재하는 경우 CP 단독 모델보다 CMTF‑OPT이 복원 정확도가 크게 향상됨을 보여준다. 또한, 반복 횟수와 실행 시간 측면에서도 ALS보다 빠른 수렴을 보이며, 대규모 데이터에도 확장 가능함을 시사한다.
이 논문의 주요 기여는 다음과 같다. 첫째, CMTF 문제를 전역 최적화 문제로 재정의하고, 효율적인 1차 최적화 기법을 적용한 CMTF‑OPT 알고리즘을 제시하였다. 둘째, 결측값 마스크를 포함한 손실함수 설계로 불완전 데이터에 대한 일반화 능력을 확보하였다. 셋째, 광범위한 실험을 통해 ALS 기반 방법보다 정확도와 수렴 속도에서 우수함을 실증하였다. 한계점으로는 (a) 비선형 제약(예: 비음수, 스파스성) 적용 시 추가적인 정규화 항이 필요하고, (b) 최적화 초기값에 따라 지역 최적점에 머무를 가능성이 존재한다는 점을 들 수 있다. 향후 연구에서는 정규화 기반의 제약을 포함한 확장, 그리고 대규모 분산 환경에서의 구현을 통해 실시간 추천 시스템 등에 적용하는 방안을 모색할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기