PDF 샘플링 최적화: 나이퀴스트‑섀넌 정리와 원자쌍 분포 함수
초록
이 논문은 원자쌍 분포 함수(PDF)의 실공간 샘플링 간격을 나이퀴스트‑섀넌 정리와 연계하여 최적화한다. 실험적으로 니켈과 복합 페롭스카이트(LaMnO₃) 데이터를 사용해 과다 샘플링과 희소 샘플링을 비교하고, 나이퀴스트 간격(drₙ=π/Qₘₐₓ) 근처에서 데이터 포인트 간 상관성이 최소가 되어 불확실성 추정이 신뢰성 있게 된다. 또한, 최적 간격보다 더 희소하게 샘플링하면 계산 속도가 크게 향상되지만, 나이퀴스트 간격보다 크게 하면 앨리어싱이 발생해 결과가 불안정해진다.
상세 분석
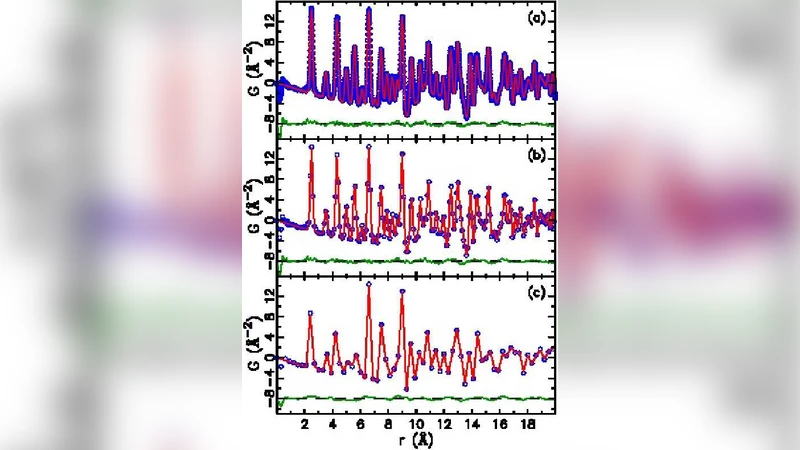
본 연구는 PDF 분석에 있어 “샘플링 간격”이라는 기본적인 파라미터가 실제로는 정보 이론적 한계에 의해 제약받는다는 점을 명확히 제시한다. PDF는 실험적으로 얻은 구조 함수 F(Q)의 제한된 Q‑범위(Qₘₐₓ)에서 푸리에 변환을 통해 얻어지며, 따라서 F(Q)의 최고 주파수는 Qₘₐₓ이다. 나이퀴스트‑섀넌 정리에 따르면, 이 주파수를 완전히 복원하려면 실공간 r‑축에서의 샘플링 간격 dr가 drₙ=π/Qₘₐₓ보다 작아야 한다. 논문은 drₙ을 “나이퀴스트 간격”이라 정의하고, dr<drₙ이면 원본 신호를 손실 없이 보간할 수 있음을 수식(4)와 함께 설명한다.
반대로 dr≥drₙ이면 고주파 성분이 저주파로 “접히는”(aliasing) 현상이 발생한다. 저자들은 이를 수학적으로 전개하여, 샘플링 간격이 drₙ보다 클 경우 F(Q)에서 Q>π/dr에 해당하는 성분이 2π/dr‑Q 로 변환되어 PDF에 잘못된 진폭을 부여함을 보여준다. 실험 데이터(Ni와 LMO)에서 dr를 단계적으로 증가시켜(0.01 Å→0.15 Å까지) PDF를 재구성하고, 동일한 구조 모델을 정밀하게 리파인먼트하였다.
핵심 결과는 다음과 같다. ① dr≈drₙ(≈0.10 Å for Ni, 0.098 Å for LMO) 근처에서는 PDF 포인트 간 상관성이 최소화되어, 레벤버그‑마르쿠아르트 최적화 과정에서 추정된 파라미터 불확실성이 실제 통계적 변동을 반영한다. ② dr를 drₙ보다 크게 하면 파라미터 변화량 Δp가 통계적 오차 σ(Δp)를 초과하는 “품질 지수” Qp>1을 보이며, 이는 모델이 실제 구조를 올바르게 설명하지 못함을 의미한다. ③ dr를 drₙ보다 작게(과다 샘플링) 하면 계산 시간이 급격히 늘어나고, 포인트 간 상관성 때문에 불확실성이 과소 추정되는 경향이 있다.
또한, 논문은 샘플링 간격이 구조 정보량 N=Δr·Qₘₐₓ/π와 직접 연결된다는 점을 강조한다. N은 이론적으로 독립적인 관측 수의 상한이며, 실제로는 신호‑대‑노이즈 비, 피크 겹침 정도 등에 따라 유효 정보량이 달라진다. 저자들은 관측‑파라미터 비(OPR)를 30:1(Ni)와 10:1(LMO) 수준으로 확보해 충분히 과잉 제약된 상황에서 실험을 수행했으며, 이는 결과의 일반성을 뒷받침한다.
전체적으로 이 연구는 PDF 분석에 있어 “몇 포인트가 필요한가?”라는 실용적 질문에 이론적 근거를 제공함과 동시에, 샘플링 전략을 최적화함으로써 계산 효율성을 크게 향상시킬 수 있음을 입증한다. 이는 고속 PDF 리파인먼트가 요구되는 대규모 데이터베이스 구축이나 실시간 구조 추적 분야에 직접적인 영향을 미칠 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기