핵과학 참고문헌(NSR) 데이터베이스와 웹 검색 시스템
초록
NSR 데이터베이스는 200 000여 편 이상의 저널·보고서를 100년 이상 포괄하는 핵과학 전용 서지 시스템으로, 고유 키워드 추출·인덱싱, MySQL 기반 관계형 저장소, Java‑Tomcat 웹 인터페이스 등을 통해 저자·핵종·반응·반감기 등 정밀 검색을 지원한다. NNDC·IAEA·맥마스터 대학이 공동 운영하며, 연간 7 00 건 이상의 질의가 이루어진다.
상세 분석
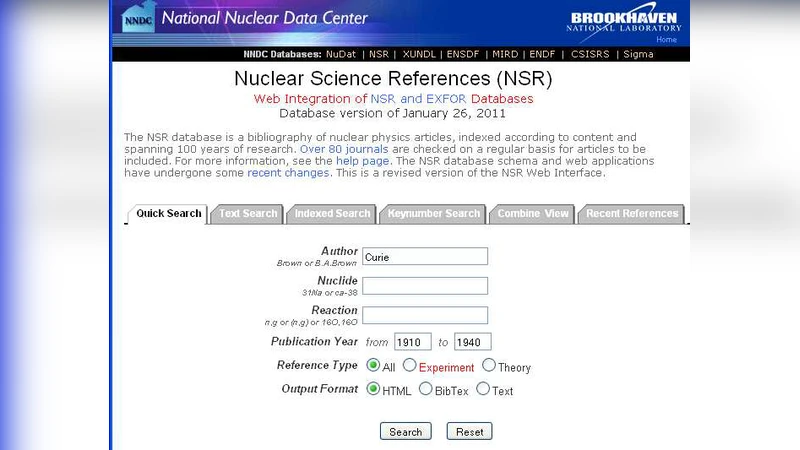
NSR는 1960년대 초 Oak Ridge에서 시작돼 현재는 NNDC(BNL), IAEA, 맥마스터 대학이 협업해 유지·보수하고 있다. 데이터는 473개 저널·다양한 회의·보고서 등에서 매주 선별·수집되며, 8자리 고유 키(ID)와 DOI, 저자·연도·제목·키워드 초록을 포함한다. 핵심은 ‘키워드 초록’이다. 컴파일러가 직접 핵종·반응·측정·계산·유도량 등을 구조화된 문장으로 기록해, Boolean 검색과 자동 인덱싱에 활용한다. 키워드 생성은 전적으로 수작업이지만 2010년부터 Apache UIMA 기반 의미분석 자동화 시도를 진행해, PDF → 텍스트 변환 → 핵심 용어 추출 과정을 반자동화하고 있다. 데이터베이스 엔진은 초기 Sybase에서 2009년 MySQL 5로 전환했으며, 현재 RedHat Linux 서버에 Java EE 2와 Tomcat 5.5, Apache 2를 결합해 안정적인 웹 서비스를 제공한다. 웹 인터페이스는 Quick Search(저자·핵종·반응·연도), Text Search(제목·키워드 전체 텍스트), Indexed Search(다중 필드 Boolean), Keynumber Search(고유 번호), Combine View(다중 결과 결합), Recent References(분기별 PDF) 등 6가지 모듈로 구성된다. 검색 결과는 HTML·Text·BibTex·PDF 형태로 다운로드 가능하고, 80 % 이상이 키워드 초록을 포함한다. NSR는 일반 검색 엔진과 달리 물리량 단위와 원소 기호를 정확히 구분해, 예를 들어 “32 Mg”와 “32 mg”를 혼동하지 않는다. 통계에 따르면 NNDC 단일 사이트에서 연간 약 2.5 백만 건의 조회가 발생했으며, 하루 평균 700 건, 한 번에 평균 800 건의 레코드가 반환된다. 이러한 규모와 정밀도는 핵 데이터 평가·컴파일·연구에 필수적인 기반을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기