대규모 상관관계 스크리닝의 위상 전이와 포아송 근사
초록
본 논문은 표본 수가 변수 수에 비해 현저히 적은 고차원 데이터에서, 상관계수 임계값 기반 스크리닝 방법을 이용해 높은 상관관계를 보이는 변수들을 효율적으로 탐지하는 이론을 제시한다. 자동상관, 교차상관, 지속상관이라는 세 가지 상황을 구분하여 각각의 위상 전이 임계값을 유도하고, 약한 의존성 가정 하에 발견 수가 포아송 분포에 의해 지배됨을 증명한다. 또한, 평균 발견 수와 허위 발견률에 대한 명시적 식을 제공하고, 대규모 유전자 발현 데이터에 적용한 실험을 통해 이론의 실효성을 검증한다.
상세 분석
논문은 먼저 고차원 데이터에서 변수 간 상관관계를 탐색하는 문제를 “스크리닝”이라는 프레임워크로 정의한다. 전통적인 전체 상관 행렬을 계산하고 분석하는 것이 계산량과 메모리 요구량 때문에 비현실적인 상황에서, 상관계수 절댓값이 사전에 정한 임계값 ρ를 초과하는 변수 쌍만을 선택함으로써 차원을 크게 축소한다. 이때 핵심 현상은 ρ가 감소함에 따라 발견되는 변수 쌍의 수가 급격히 증가하는 ‘위상 전이(phase transition)’이다. 저자는 이 전이점 ρ_c 를 p(변수 수), n(표본 수) 및 변수들의 공동분포에 대한 함수로 정확히 추정한다.
세 가지 스크리닝 시나리오—자동상관(동일 처리 내 변수 간), 교차상관(두 처리 간 변수 간), 지속상관(두 처리 모두에서 높은 자동상관을 유지)—에 대해 각각의 임계값 ρ_c 를 유도한다. 특히, 자동상관의 경우 n>4 일 때 ρ_c ≈ 1−C·p^{−1/n} 형태이며, C는 Bhatta‑Charyya 측정값(평균 쌍별 의존성)과 약하게 연관된다. 이는 변수 수가 급증하거나 표본 수가 감소할수록 ρ_c 가 1에 접근해 스크리닝이 무의미해지는 위험을 정량화한다.
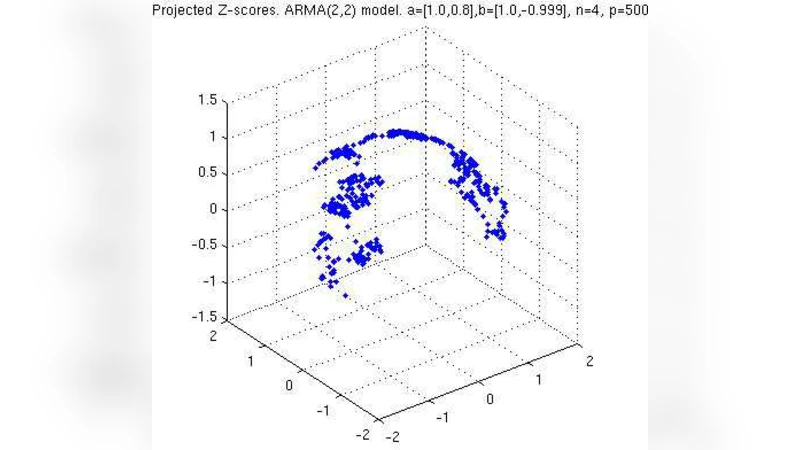
수학적 도구로는 (n−2) 차원의 구면 위에 놓인 U‑score 를 도입한다. U‑score 는 표본 평균과 분산을 정규화한 뒤, 행렬 H 를 통해 구면에 투사한 벡터이며, 샘플 상관계수 r_{ij}=U_i^T U_j 로 표현된다. 이 구면 기하학을 이용해 두 변수 간 상관이 ρ 이상일 확률을 구면 캡 면적 P_0(ρ,n) 로 근사하고, 이를 통해 평균 발견 수 E
댓글 및 학술 토론
Loading comments...
의견 남기기