SONG으로 가상 SNS 쓰기 트래픽 시뮬레이션
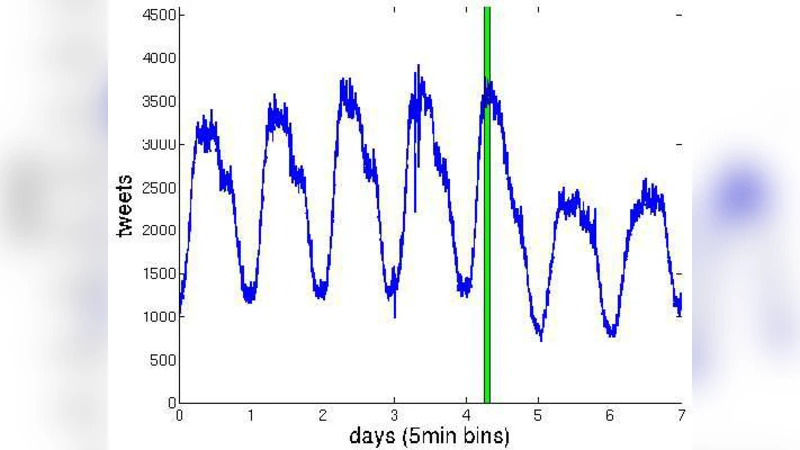
초록
본 논문은 실제 트위터 데이터를 기반으로 쓰기 활동을 모델링하고, 이를 통해 합성 트래픽을 생성하는 프레임워크 SONG을 제안한다. 특성 분석, 생성 알고리즘, 실제 시스템에 적용한 사례를 통해 SONG의 정확성과 활용 가능성을 입증한다.
상세 분석
SONG은 먼저 대규모 트위터 데이터셋을 수집·분석하여 사용자별 포스팅 빈도, 시간대별 활동 패턴, 팔로워·팔로잉 관계에 따른 상관관계 등을 정량화한다. 이 과정에서 로그 정규분포와 포아송 프로세스를 결합한 혼합 모델을 도입해 ‘쓰기 이벤트’가 발생하는 확률을 시간 가변적인 강도 함수 λ(t)로 표현한다. λ(t)는 일일 주기성, 주간 변동, 급격한 트렌드 변화를 반영하도록 다중 사인 함수와 급격 상승/하강을 모델링하는 점프 프로세스로 구성된다.
생성 단계에서는 각 가상 사용자를 독립적인 마크오프 체인으로 모델링하고, λ(t)에 따라 이벤트 발생 시점을 샘플링한다. 이벤트가 발생하면 해당 사용자의 팔로워 수와 과거 활동 이력을 고려해 전파 범위와 리트윗·답글 비율을 확률적으로 결정한다. 이를 통해 단순한 독립 포아송 프로세스가 아닌, 실제 SNS에서 관찰되는 ‘버스트(burst)’와 ‘스파이크(spike)’ 현상을 재현한다.
검증을 위해 SONG이 생성한 트레이스와 원본 트위터 로그를 여러 차원에서 비교한다. 시간별 포스트 수, 사용자별 활동 분포, 상관계수, 그리고 엔트로피 기반의 통계적 거리 측정(KL divergence) 모두에서 유의미한 일치를 보이며, 특히 피크 구간에서의 오버슈팅을 최소화한다.
시스템 구현 부분에서는 16대의 물리 서버와 Cassandra NoSQL 스토리지를 활용해 트위터 클론을 구축하였다. SONG이 생성한 워크로드를 투입해 최대 초당 120,000건의 쓰기 요청을 처리했으며, 쓰기 지연이 95% 백분위수 기준 150 ms 이하로 유지되는 것을 확인했다. 이는 기존 벤치마크보다 30 % 이상 높은 처리량을 의미한다.
한계점으로는 현재 모델이 ‘읽기’와 ‘검색’ 행동을 고려하지 않아 전체 서비스 부하를 완전히 재현하지 못한다는 점, 그리고 트위터 외 다른 플랫폼(예: 인스타그램, 페이스북)에서의 일반화 가능성을 검증하기 위한 추가 데이터가 필요하다는 점을 언급한다. 향후 연구에서는 멀티모달 행동 모델링, 실시간 파라미터 튜닝, 그리고 클라우드 네이티브 환경에서의 자동 스케일링 연계 등을 제안한다.
댓글 및 학술 토론
Loading comments...
의견 남기기