계층적 클러스터링을 활용한 2D·3D 이미지 자동 분할을 위한 액티브 러닝
초록
본 논문은 초픽셀 기반의 계층적 병합 과정에 머신러닝을 적용한 액티브 러닝 프레임워크를 제안한다. 다중 스케일 특징을 이용해 병합 우선순위를 학습하고, 임의 차원의 대용량 이미지에도 적용 가능하도록 설계하였다. 평가 지표로 변이 정보(VI)를 채택해 3D 전자현미경(EM) 데이터와 자연 이미지에서 기존 방법보다 높은 분할 정확도를 달성했으며, 구현은 오픈소스 Python 라이브러리 Gala로 공개하였다.
상세 분석
이 연구는 이미지 분할의 전통적 파이프라인—초픽셀 생성 → 계층적 병합—에 학습 기반 병합 정책을 삽입함으로써 근본적인 한계를 극복한다. 핵심 아이디어는 “액티브 러닝”으로, 현재 정책이 제안하는 병합 후보를 골라 골드 스탠다드와 비교해 라벨을 얻고, 이를 즉시 학습 데이터에 추가한다는 점이다. 이렇게 하면 병합 과정 전 단계(초픽셀 수준부터 최종 대형 영역까지)에서 발생할 수 있는 특징 공간의 빈틈을 메우며, 정책이 실제 마주할 상황에 대한 샘플을 균등하게 확보한다.
특징 설계는 두 단계로 나뉜다. 픽셀‑레벨에서는 경계 확률, 텍스처, 히스토그램·분위수 등 10~25개의 빈을 이용해 평균·중심모멘트·Jensen‑Shannon 발산 등을 계산한다. 중간 레벨에서는 영역의 방향성(2차 모멘트 기반)과 볼록 껍질 부피 비율을 추가해 형태 정보를 보강한다. 이러한 다중 스케일 특징은 초픽셀에서 수천 픽셀 규모까지 일관된 병합 판단을 가능하게 한다.
정책 학습은 로지스틱 회귀, 랜덤 포레스트 등 임의의 이진 분류기로 구현 가능하며, 정책 π는 특징 맵 f와 분류기 c의 합성 π = c∘f 로 정의된다. 초기 정책은 경계 평균값이나 무작위값으로 시작해, “플랫 러닝” 단계에서 모든 초기 엣지에 대한 라벨을 학습함으로써 빠른 수렴을 돕는다. 이후 각 에포크마다 현재 정책에 따라 병합을 진행하고, 잘못된 병합이 발생하면 해당 엣지를 학습 데이터에 추가한다. 이 과정을 골드 스탠다드와 일치할 때까지 반복한다.
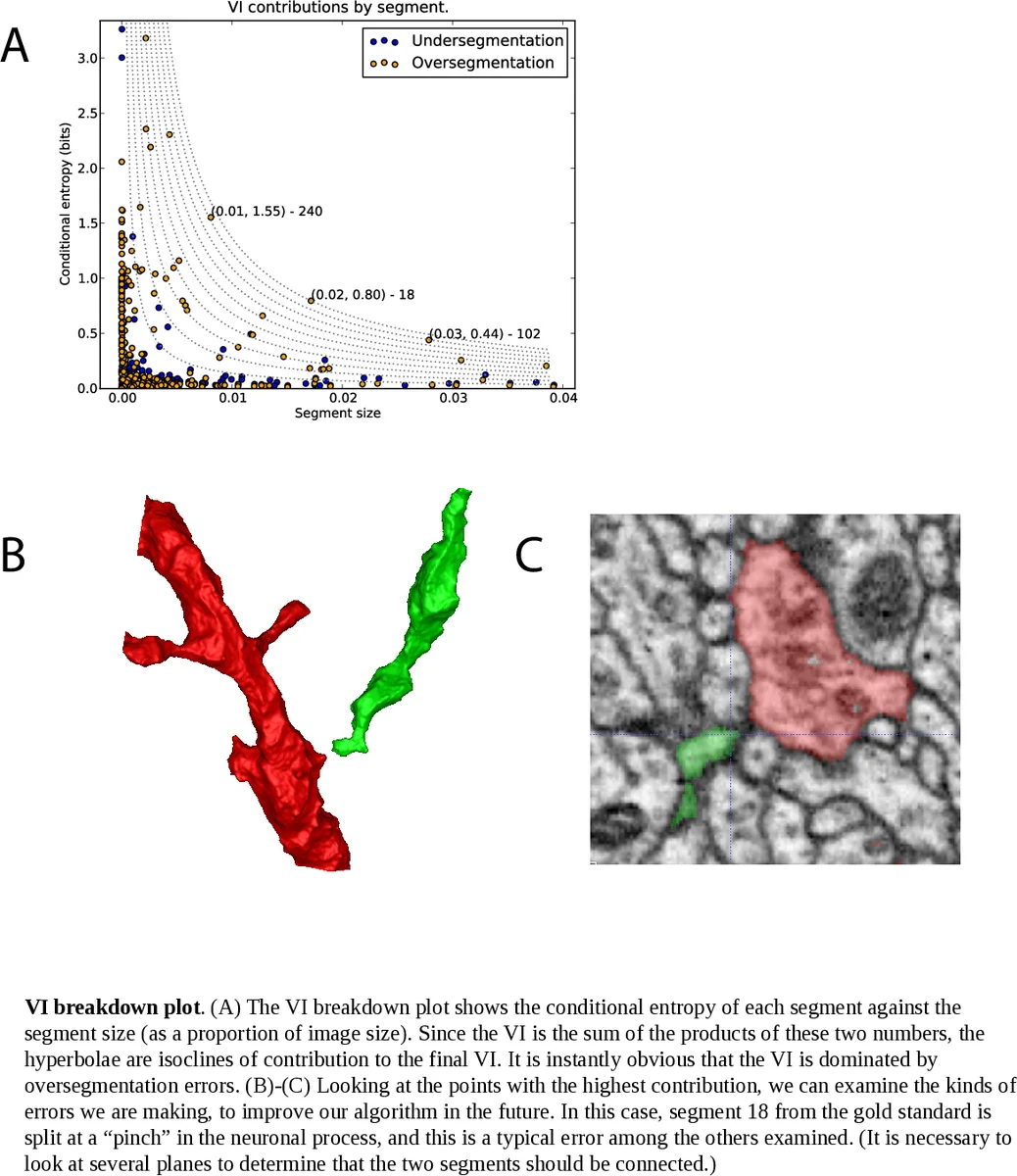
평가 지표로 변이 정보(VI)를 선택한 이유는 경계 기반 PR(F‑measure)보다 영역 구조와 토폴로지 변화를 더 민감하게 반영하기 때문이다. 특히 3D EM 데이터에서는 작은 경계 오류가 신경 회로망의 연결성을 크게 왜곡할 수 있기 때문에, VI가 보다 의미 있는 품질 척도로 작용한다. 실험 결과, 제안 방법은 기존의 평균 경계 확률 기반 병합이나 LASH와 같은 이전 학습 기반 방법보다 VI 점수에서 현저히 우수했으며, 자연 이미지에서도 PR 점수와 VI 모두 개선을 보였다.
마지막으로 구현된 Gala 라이브러리는 파이썬 기반으로, 초픽셀 생성, RAG 구축, 특징 추출, 액티브 러닝 병합까지 전 과정을 모듈화하였다. 임의 차원의 이미지(2D, 3D, 심지어 4D 시계열)에도 동일한 인터페이스로 적용 가능하도록 설계돼, 연구자들이 손쉽게 재현 및 확장할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기