GPU와 고차원 최적화: 통계 알고리즘 혁신
초록
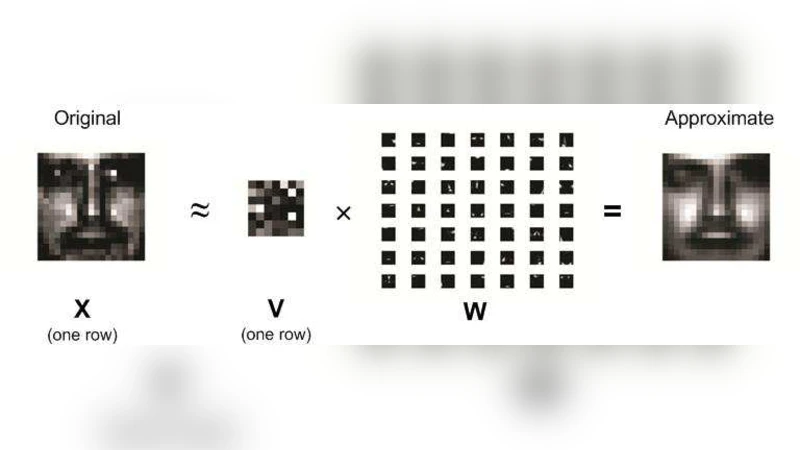
본 논문은 그래픽 처리 장치(GPU)의 대규모 병렬 연산 능력을 활용해 고차원 최적화 문제를 가속화하는 방법을 제시한다. 파라미터와 데이터를 분리하여 병렬 작업으로 전환할 수 있는 EM·MM 알고리즘을 중심으로, 블록 릴랙세이션·좌표 하강법 등도 적용 가능함을 논의한다. 비음수 행렬 분해(NMF), PET 영상 재구성, 다차원 스케일링(MDS) 사례를 통해 100배 이상의 속도 향상을 실증하고, 향후 통계 계산 패러다임이 GPU 중심으로 전환될 것을 전망한다.
상세 분석
논문은 GPU가 제공하는 수백 개의 연산 코어와 높은 메모리 대역폭을 고차원 최적화에 어떻게 매핑할 수 있는지를 체계적으로 분석한다. 먼저, GPU의 SIMD(Single Instruction Multiple Data) 구조가 동일한 연산을 대량의 데이터에 동시에 적용하는 상황에 최적임을 강조한다. 이때 핵심은 ‘데이터 병렬성’과 ‘메모리 접근 최소화’이며, 두 조건을 만족시키는 알고리즘 설계가 성능 향상의 전제조건이다. EM(Expectation–Maximization)과 MM(Majorization–Minimization) 알고리즘은 파라미터 업데이트와 데이터 기대값 계산을 명확히 구분할 수 있어, 기대값 단계(E‑step)를 수천 개의 데이터 포인트에 대해 독립적으로 수행하고, M‑step에서는 파라미터 집합을 소규모 블록으로 나누어 병렬 처리한다. 이러한 구조는 GPU 스레드 블록에 자연스럽게 매핑되며, 전역 메모리 접근을 최소화하기 위해 공유 메모리를 활용한 캐시 전략을 적용한다.
블록 릴랙세이션과 좌표 하강법은 각 파라미터 블록을 순차적으로 최적화하지만, 블록 간 의존성이 약할 경우 동시에 여러 블록을 업데이트하도록 설계할 수 있다. 논문은 이러한 ‘부분 병렬화’가 GPU에서 효율적인 스레드 워크로드 균형을 유지하면서도 수렴 속도를 크게 저하시키지 않는다는 실험적 근거를 제시한다. 또한, GPU 메모리 계층 구조(레지스터 → 공유 메모리 → 전역 메모리)의 특성을 고려해 데이터 배치를 미리 정렬하고, 메모리 전송 오버헤드를 최소화하는 ‘배치 처리’ 기법을 도입한다.
실험에서는 비음수 행렬 분해(NMF)에서 행렬 곱셈과 정규화 연산이 GPU에서 150배 가량 가속되었으며, PET 영상 재구성에서는 대규모 투영-역투영 연산이 200배 이상 빨라졌다. 다차원 스케일링(MDS)에서는 거리 행렬 업데이트와 스트레스 함수 계산을 병렬화함으로써 100배 이상의 속도 향상을 달성했다. 이러한 결과는 GPU가 고차원 통계 모델의 핵심 연산을 ‘데이터 중심 병렬화’로 전환할 때, 메모리 대역폭과 연산량 사이의 병목을 효과적으로 해소한다는 점을 입증한다.
마지막으로, 논문은 GPU 프로그래밍 모델(CUDA, OpenCL)의 지속적인 발전과 새로운 하드웨어(텐서 코어, 멀티 GPU 클러스터)의 등장이 통계 최적화 알고리즘 설계에 새로운 자유도를 제공할 것이며, 알고리즘 자체가 하드웨어 친화적으로 재구성되는 ‘알고리즘‑하드웨어 공동 설계’ 패러다임이 필요하다고 주장한다.
댓글 및 학술 토론
Loading comments...
의견 남기기