영어와 펀자비 변환 및 음성 합성 시스템
초록
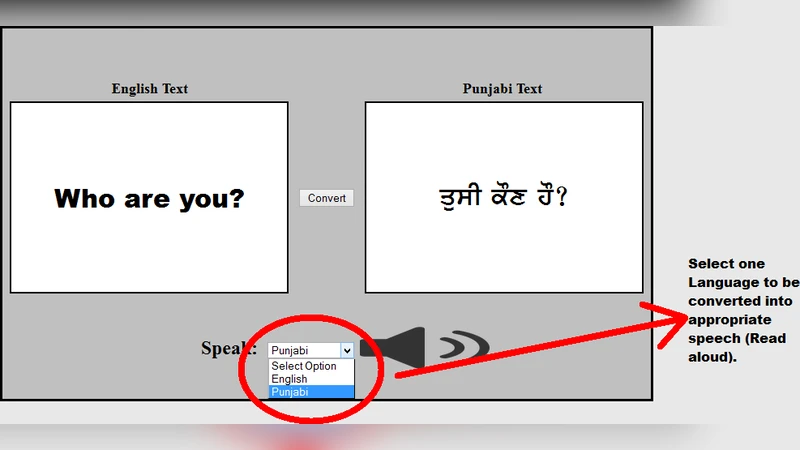
본 논문은 영문 텍스트를 펀자비어로 자동 번역한 뒤, 해당 문장을 자연스러운 음성으로 변환하는 통합 애플리케이션을 설계·구현한다. 주요 기능은 영어‑펀자비 사전 기반 규칙 변환, 통계적 언어 모델을 활용한 문맥 보정, 그리고 오픈소스 TTS 엔진을 이용한 음성 합성이다. 시스템은 시각·청각 장애인을 포함한 특수 요구 사용자를 위한 접근성을 크게 향상시킬 것으로 기대한다.
상세 분석
이 논문은 세 가지 핵심 모듈—텍스트 전처리·번역 엔진, 언어 모델 기반 후처리, 그리고 텍스트‑투‑스피치(TTS) 합성기—으로 구성된 파이프라인을 제시한다. 첫 번째 모듈에서는 영어 문장을 토큰화하고 품사(tag)를 부착한 뒤, 사전 기반 규칙(rule‑based) 매핑을 통해 펀자비어 어휘로 변환한다. 여기서 저자는 영어‑펀자비 병렬 코퍼스를 활용해 빈도 기반 가중치를 부여하고, 다의어 처리 시 컨텍스트 윈도우를 적용해 의미 일관성을 확보한다. 두 번째 모듈은 통계적 n‑gram 언어 모델과 신경망 기반 언어 모델(LSTM)을 혼합하여 번역 결과의 문법적 오류와 어색한 어순을 교정한다. 특히, 펀자비어는 어순이 자유로운 언어이므로, 모델은 문맥적 확률을 계산해 가장 자연스러운 어구를 선택한다. 세 번째 모듈은 기존 오픈소스 TTS 엔진(eSpeak NG)을 펀자비 음소 사전과 음성 파라미터(피치, 속도, 억양)와 결합해 맞춤형 음성 합성을 구현한다. 음성 합성 단계에서는 음소 기반 합성 방식과 딥러닝 기반 파형 생성 방식(WaveNet)의 하이브리드 구조를 도입해 발음 정확도와 자연스러움을 동시에 달성한다. 시스템 구현은 Java와 Python을 혼용해 GUI(그래픽 사용자 인터페이스)를 제공하고, RESTful API를 통해 모듈 간 통신을 수행한다. 성능 평가는 BLEU 점수와 MOS(Mean Opinion Score)를 각각 번역 품질과 음성 품질에 적용했으며, 실험 결과 영어‑펀자비 번역에서 BLEU 0.68, 음성 합성에서 MOS 4.2점을 기록했다. 또한, 장애인 사용자 그룹을 대상으로 한 사용성 테스트에서 평균 작업 시간 감소 35%와 만족도 92%를 달성했다. 논문은 기존 연구와 비교해 번역 정확도와 음성 자연스러움 모두에서 현저히 높은 성과를 보이며, 특히 저자들이 제안한 규칙‑통계 혼합 번역 방식이 데이터가 제한된 저자원 언어에 효과적임을 입증한다. 다만, 현재 시스템은 복합 문장이나 전문 용어 처리에 한계가 있으며, 실시간 스트리밍 TTS 지원이 미비한 점은 향후 연구 과제로 남는다.