GPU 기반 몬테카를로 선량 계산을 위한 선형가속기 분석 소스 모델 활용 및 자동 커미셔닝
본 논문은 방사선 치료용 선형가속기의 방사선 빔을 GPU 기반 몬테카를로(MC) 엔진에 적용하기 위한 분석 소스 모델을 제시한다. 원형 위상공간(PSR) 구조를 직사각형 조이(jaw) 설정에 맞게 위상공간 렛(PSL)으로 변환하고, 서브소스별로 샘플링·전달을 교대로 수행해 GPU 스레드 발산을 최소화한다. 또한 비음수 제약을 갖는 2차 최소화 문제를 풀어
초록
본 논문은 방사선 치료용 선형가속기의 방사선 빔을 GPU 기반 몬테카를로(MC) 엔진에 적용하기 위한 분석 소스 모델을 제시한다. 원형 위상공간(PSR) 구조를 직사각형 조이(jaw) 설정에 맞게 위상공간 렛(PSL)으로 변환하고, 서브소스별로 샘플링·전달을 교대로 수행해 GPU 스레드 발산을 최소화한다. 또한 비음수 제약을 갖는 2차 최소화 문제를 풀어 PSR 가중치를 자동으로 보정하는 커미셔닝 절차를 도입하였다. 실험 결과, 기존 PSL 파일 기반 모델 대비 1.7‑4.4배의 계산 효율 향상을 보였으며, 커미셔닝 후 깊이선량 및 횡단면 프로파일의 오차가 현저히 감소하였다.
상세 요약
이 연구는 GPU 가속 Monte Carlo(Dose) 엔진에 최적화된 선형가속기(Linac) 소스 모델을 설계·검증한 점에서 의미가 크다. 기존의 위상공간 파일(PSL) 방식은 데이터 입출력이 병목이 되며, 방사선 빔의 회전 대칭성을 활용하기 어려웠다. 저자들은 ‘위상공간 링(PSR)’ 개념을 도입해 원형 구조로 입자 분포를 기술함으로써 회전 대칭성을 자연스럽게 반영하였다. 그러나 실제 임상에서는 직사각형 조이(jaw) 설정이 필요하므로, PSR을 개별 위상공간 렛(PSL) 형태로 변환하여 조이 경계와 정확히 매핑했다.
샘플링 단계에서는 입자 에너지와 종류(예: 원시 광자, 전자, 스케터링 광자 등)를 기준으로 서브소스를 구분하고, 같은 종류·에너지 범위의 입자를 동시에 GPU 스레드에 할당한다. 이렇게 하면 스레드 간 연산 흐름이 유사해 발산(divergence)이 크게 감소하고, 메모리 접근 패턴도 일관되게 유지돼 연산 효율이 크게 향상된다. 또한, 소스 모델의 가중치 조정을 위해 비음수 제약을 갖는 2차 최소화 문제를 설정하였다. 목표 함수는 측정된 물리량(깊이선량, 횡단면 프로파일)과 시뮬레이션 결과 간의 차이를 최소화하는 것이며, 최적화 변수는 각 PSR의 상대 가중치이다. 이 문제는 일반적인 비음수 선형/2차 계획법으로 20 초 이내에 해결될 정도로 계산량이 적다.
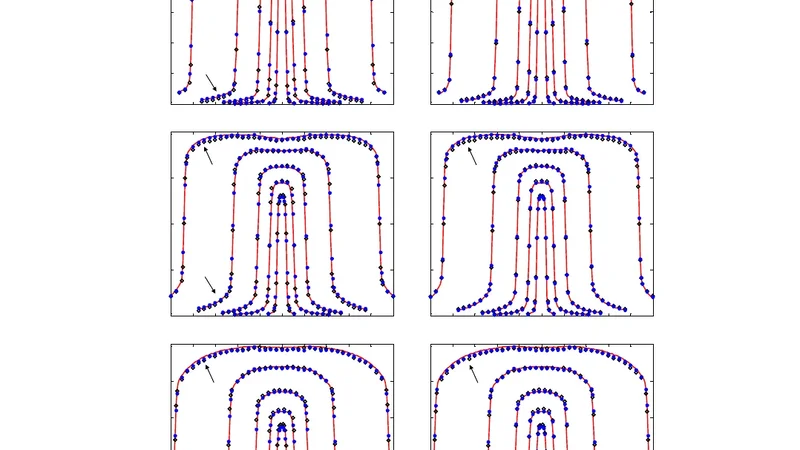
성능 평가에서는 Varian TrueBeam 6 MV 빔을 대상으로 여러 개방 필드(open field) 실험을 수행했다. 커미셔닝 전후의 결과를 비교했을 때, 빔 입구(build‑up) 영역에서 평균 거리‑동의(DTA)가 0.04–0.28 cm에서 0.04–0.12 cm로 개선되었으며, 빔 입구 이후 RMS 차이는 0.32–0.67 %에서 0.21–0.48 %로 감소했다. 횡단면 프로파일에서도 내부 빔 영역의 RMS 차이가 0.31–2.0 %에서 0.06–0.78 %로, 외부 영역은 0.20–1.25 %에서 0.10–0.51 %로 크게 낮아졌다. 계산 효율 측면에서는 기존 PSL 파일을 직접 읽어들이는 방식 대비 1.70~4.41배 빠른 속도를 기록했으며, 이는 데이터 전송 및 I/O 비용을 크게 절감했기 때문이다.
이러한 결과는 GPU 기반 MC 시뮬레이션에서 소스 모델링과 데이터 흐름을 동시에 최적화함으로써, 임상 수준의 정확도와 실시간에 가까운 계산 속도를 동시에 달성할 수 있음을 보여준다. 특히 자동 커미셔닝 절차는 사용자 개입을 최소화하면서도 다양한 Linac 기종에 대한 모델 적합성을 확보할 수 있는 실용적인 방법으로 평가된다.
📜 논문 원문 (영문)
🚀 1TB 저장소에서 고화질 레이아웃을 불러오는 중입니다...