온라인 환경에서도 경쟁력 있는 K‑means 클러스터링 알고리즘
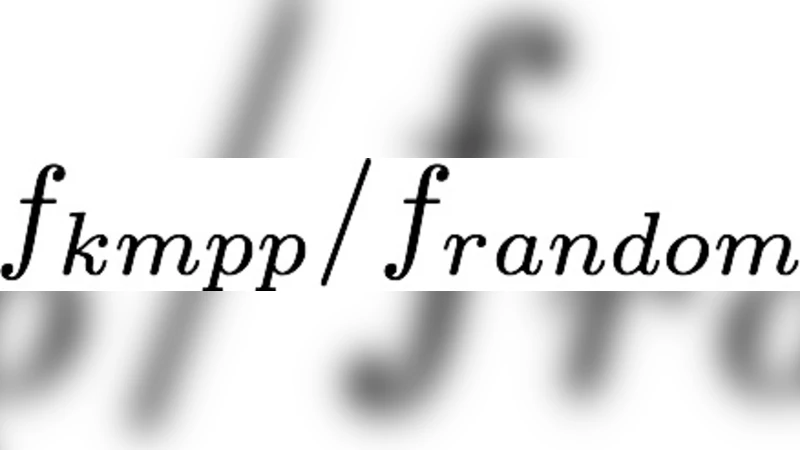
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
**
이 논문은 데이터가 순차적으로 도착하는 온라인 모델에서, 약 O(k)개의 클러스터를 생성하면서 최적 k‑means 비용 W에 대해 다항 로그 차이만큼의 근사비용을 보장하는 두 가지 알고리즘을 제시한다. 반(半)온라인 버전은 사전 지식 w와 n을 이용해 기대 비용 O(W*)와 클러스터 수 O(k log n log (W*/w*))를 달성하고, 완전 온라인 버전은 추가적인 로그 n 인자를 포함해 O(W* log n) 비용을 보장한다. 실험에서는 k‑means++와 비교해 성능 저하가 미미함을 확인한다.
**
상세 분석
**
본 논문은 온라인·반온라인 클러스터링이라는 두드러진 난제를 시설 위치(facility location) 문제와의 연관성을 통해 해결한다. 핵심 아이디어는 각 클러스터를 ‘시설’이라 보고, 새로운 점이 도착할 때마다 그 점과 현재 시설 집합 C 사이의 최소 제곱거리 D²(v,C)를 계산한다. 이 거리가 현재 ‘시설 비용’ f_r에 비해 충분히 크면(확률 p = min{D²(v,C)/f_r, 1}) 새로운 시설을 열어 클러스터를 생성한다. 초기 f₁은 매우 작게 설정해 과도한 시설 개설을 유도하고, 일정 수(≈3k(1+log n))의 클러스터가 생성될 때마다 f_r을 두 배로 늘리는 방식으로 비용을 조절한다.
반온라인 알고리즘(Algorithm 1)은 전체 스트림 길이 n과 최적 비용의 하한 w를 사전에 알고 있다는 가정 하에, 초기 시설 비용을 f₁ = w/(k log n)으로 설정한다. 이때 기대 클러스터 수는
E
댓글 및 학술 토론
Loading comments...
의견 남기기