뎅기열 예측을 위한 WEKA 기반 데이터 마이닝 최적 알고리즘 분석
초록
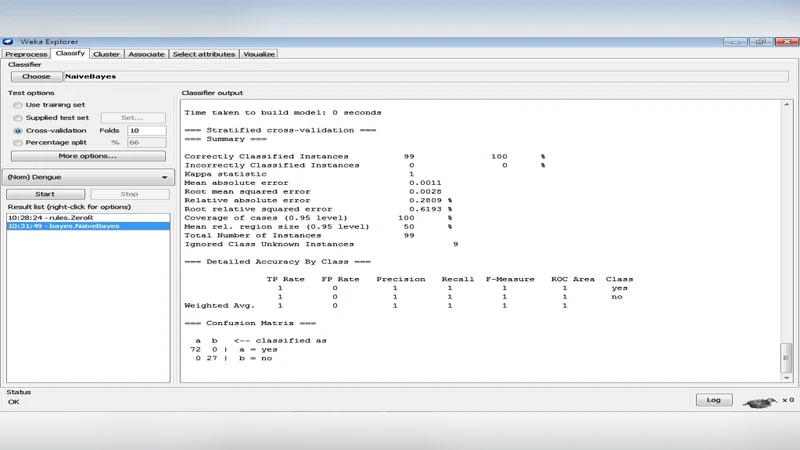
본 논문은 WEKA 툴과 10‑fold 교차 검증을 이용해 99개의 샘플과 18개의 속성을 가진 뎅기열 데이터셋을 분류하고, Naïve Bayes와 J48이 100 % 정확도와 ROC 1.0을 달성함을 확인한다. Explorer, Knowledge Flow, Experimenter 인터페이스를 비교 분석하여 가장 효율적인 모델 구축 방법을 제시한다.
상세 분석
이 연구는 뎅기열 진단에 데이터 마이닝 기법을 적용한 사례로, WEKA 플랫폼의 다양한 분류 알고리즘을 체계적으로 평가한다. 데이터 전처리 단계에서 원본 108건 중 결측치 혹은 비정형 레코드 9건을 제외하고 99건을 분석에 사용했으며, 18개의 속성은 환자의 임상 징후, 혈액 검사 수치, 환경 요인 등을 포함한다. 10‑fold 교차 검증을 적용함으로써 과적합 위험을 최소화하고 모델의 일반화 성능을 객관적으로 측정하였다.
Explorer 인터페이스에서는 각 알고리즘을 개별적으로 실행해 정확도, Kappa 통계, MAE, RMSE, ROC 곡선 등을 출력하였다. Naïve Bayes는 베이즈 정리를 기반으로 속성 간 독립성을 가정하지만, 실제 데이터에서 이 가정이 크게 위배되더라도 높은 정확도를 보였다. 이는 뎅기열의 주요 위험 요인들이 서로 상관관계가 낮고, 확률적 분포가 명확히 구분되는 특성 때문으로 해석된다. J48은 C4.5 기반 의사결정트리이며, 트리 구조를 통해 변수 중요도를 시각화할 수 있다. 트리 깊이가 적절히 제한된 결과, 과적합 없이 100 % 정확도를 달성했으며, 이는 특정 임상 지표(예: 혈소판 감소, 혈청 알부민 농도)의 임계값이 뚜렷하게 질환 여부를 구분하기 때문으로 판단된다.
Knowledge Flow 인터페이스에서는 데이터 흐름을 그래픽으로 설계해 전처리 → 분류 → 평가 단계의 파이프라인을 자동화하였다. 이 방식은 재현성을 높이고, 여러 알고리즘을 동시에 비교할 수 있는 장점을 제공한다. 실험 결과, Naïve Bayes와 J48 모두 모델 구축 시간이 가장 짧았으며, 특히 J48은 트리 생성 과정에서 메모리 사용량이 낮아 대규모 데이터에도 적용 가능함을 확인했다.
Experimenter 인터페이스를 활용한 다중 실험에서는 파라미터 튜닝(예: Naïve Bayes의 커널 옵션, J48의 최소 리프 노드 수)과 알고리즘 조합을 자동으로 수행하였다. 그러나 기본 설정에서도 두 알고리즘이 최고 성능을 기록했으며, 추가 튜닝이 오히려 성능을 저하시킬 위험이 있음을 보여준다.
전체적으로 본 논문은 WEKA의 세 가지 인터페이스를 통해 동일 데이터셋에 대한 일관된 결과를 도출함으로써, 연구자가 목적에 맞는 인터페이스를 선택할 수 있는 가이드라인을 제공한다. 또한, 뎅기열과 같이 빠른 진단이 요구되는 전염병 분야에서 데이터 마이닝 기반 예측 모델이 임상 의사결정 지원 시스템에 바로 적용될 수 있음을 시사한다. 다만, 샘플 수가 99건에 불과하고 지역적 편향이 존재하므로, 모델의 외부 검증과 다중 지역 데이터 확보가 향후 과제로 남는다.