맥스DNN: 맥스웰 GPU용 고효율 컨볼루션 커널
초록
맥스DNN은 NVIDIA Maxwell 아키텍처를 대상으로 설계된 어셈블리 기반 컨볼루션 커널이다. Maxas SGEMM 구현 기법과 cuda‑convnet2의 메모리 레이아웃을 결합해 전방 전파(FPROP)에서 평균 96 % 이상의 연산 효율을 달성한다. 실험 결과 AlexNet·OverFeat와 같은 대표적인 이미지 분류 모델의 모든 레이어에서 cuDNN 대비 현저히 높은 효율을 보이며, 특히 필터·배치 크기가 64의 배수일 때 최적 성능을 유지한다.
상세 분석
본 논문은 GPU 기반 딥러닝에서 가장 핵심적인 연산인 2‑D 컨볼루션을 어떻게 하면 하드웨어 한계에 가까운 연산 효율로 구현할 수 있는지를 상세히 탐구한다. 핵심 아이디어는 세 가지로 요약할 수 있다. 첫째, cuda‑convnet2가 제안한 “채널‑우선” 메모리 정렬 방식을 그대로 채택해 입력 이미지와 필터를 각각 N_b × S²_k N_c와 S²_k N_c × N_o 형태의 행렬로 변환한다. 이때 내부 루프는 실제 행렬 곱셈과 동일하게 동작하지만, 기존 구현에서는 비연속 메모리 접근을 위해 복잡한 인덱스 연산이 필요했다. 둘째, Maxas 프로젝트에서 제공하는 SGEMM64 어셈블리 코드를 기반으로, 각 워프가 64 × 64 블록을 처리하도록 설계하였다. 여기서 중요한 최적화는 (1) 128‑bit 텍스처 로드 명령을 이용해 전역 메모리 읽기 횟수를 최소화하고, (2) 전역·공유 메모리 로드를 이중 버퍼링하여 레이턴시를 완전히 숨김으로써 연산 파이프라인을 포화시켰다는 점이다. 셋째, 픽셀·채널 오프셋을 상수 메모리에 미리 저장하고, 루프 내부에서는 사전 계산된 오프셋을 단순히 더하는 방식으로 인덱싱 비용을 3중 루프에서 1중 루프로 축소했다. 이 결과 내부 루프의 부동소수점 명령 비중이 98.3 %에 달했으며, 전체 커널의 연산 효율은 96.3 %에 이른다.
논문은 또한 효율성 측정 방법을 명확히 정의한다. “컴퓨테이셔널 효율성”을 실제 수행된 FLOP 대비 이론적 피크 FLOP 비율로 계산하고, 불필요한 부동소수점 연산(예: 패딩 처리 등)까지 포함하면 효율이 과대평가될 수 있음을 지적한다. 이를 보정하기 위해 실제 컨볼루션 연산에 필요한 FLOP만을 기준으로 효율을 재계산하였다.
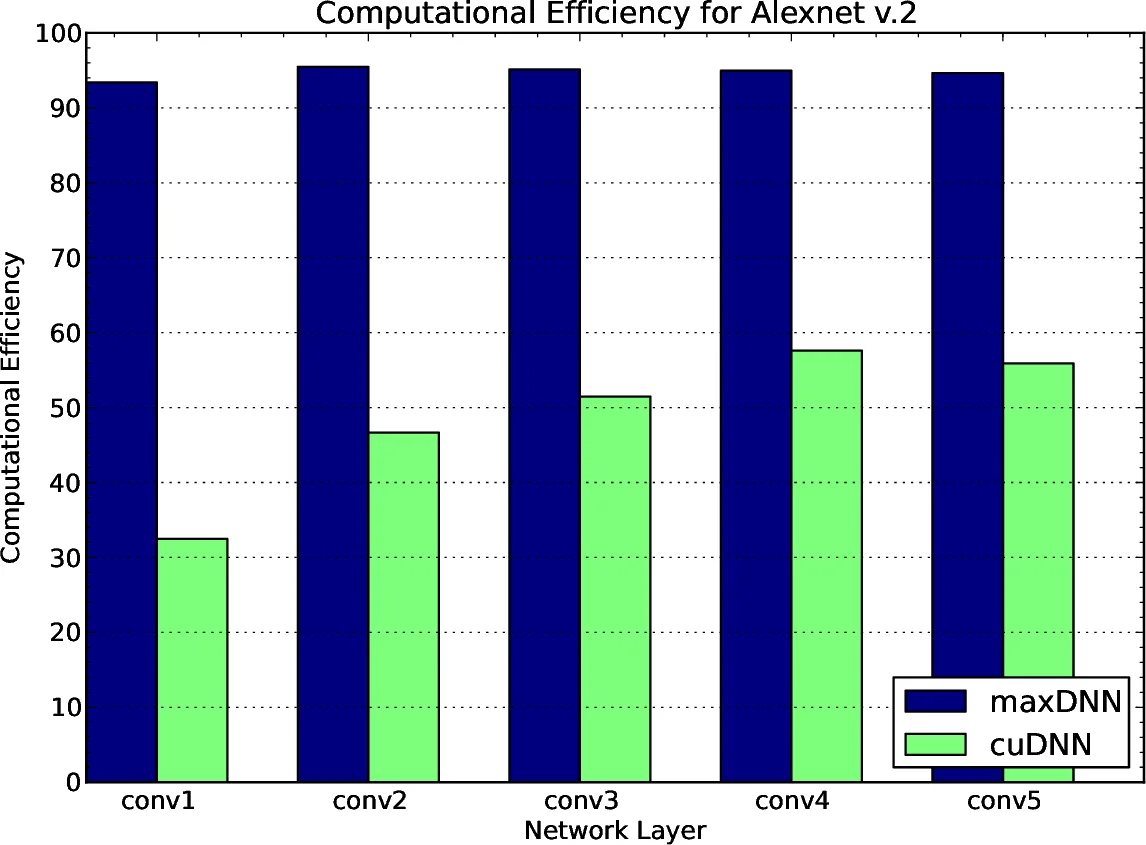
실험에서는 GTX 980 (GM204)에서 cuDNN v2 RC1과 직접 비교했으며, AlexNet‑v2와 OverFeat 두 모델을 대상으로 128 배치 크기에서 테스트했다. 결과는 대부분의 레이어에서 maxDNN이 93 %~96 %의 효율을 보인 반면, cuDNN은 32 %~75 % 수준으로 크게 뒤처졌다. 특히 첫 번째 레이어는 필터 수가 64의 배수가 아니고, 입력 패치가 작아 인덱싱 오버헤드가 크게 작용해 효율이 낮아졌다(70 % 수준). 저자는 블록 크기를 64 × 32 등으로 다양화하면 이러한 문제를 완화할 수 있다고 제안한다.
마지막으로, 논문은 현재는 전방 전파만 구현했지만, 동일한 어셈블리 기반 접근법을 역전파(BPROP)에도 적용하면 비슷한 수준의 효율을 기대할 수 있다고 주장한다. 이는 기존 cuDNN이 단일 커널로 다양한 레이어와 배치 크기를 포괄하려다 보니 효율이 떨어지는 문제를 어셈블리 수준에서 해결한 사례라 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기