실시간 트위터 신뢰도 평가 시스템 트윗크레드
초록
트윗크레드는 위기 상황에서 트위터에 퍼지는 허위·루머 정보를 자동으로 판단하기 위해, 45개의 실시간 추출 가능한 특징을 활용한 반지도 학습 순위 모델을 적용한 브라우저 플러그인이다. 1,127명의 사용자를 대상으로 5.4백만 트윗에 대한 신뢰도 점수를 제공했으며, 평균 응답 시간 6초 이내, 사용자는 63%가 점수에 동의하거나 1~2점 차이로 수용하였다.
상세 분석
본 논문은 위기 상황에서 급증하는 트위터상의 허위·루머 문제를 해결하고자, 기존의 오프라인 분류 접근법을 넘어 실시간으로 신뢰도 점수를 산출하는 시스템을 설계하였다. 핵심은 반지도 학습(semisupervised learning) 기반의 순위 모델이며, 이를 구현하기 위해 SVM‑rank를 선택하였다. 학습 데이터는 2013년 발생한 6대 재난·사건(보스턴 마라톤 폭탄테러, 하이얀·욜란다 태풍 등)으로부터 스트리밍 API를 이용해 수집한 10 백만 트윗 중 무작위로 3 천여 개를 선정, 크라우드플로워를 통해 두 단계 라벨링을 수행하였다. 첫 단계에서는 트윗이 사건과 관련 있는지(R1‑R3) 판단하고, R1에 해당하는 45%를 대상으로 두 번째 단계에서 신뢰도(C1‑C3) 라벨을 부여하였다.
특징 설계는 총 45개로, 메타데이터(시간, 소스, 지리정보), 텍스트 형태(문자·단어 수, URL·해시태그·감정 단어·욕설·스마일리 등), 사용자 속성(팔로워·팔로잉·계정 연령), 네트워크 지표(리트윗·멘션·답글 여부) 및 외부 평판(WOT 점수) 등을 포함한다. 특히 “via” 문자열, 문자·단어 수, 고유 문자 수, 사용자 위치 정보, 리트윗 수 등이 상위 10개 특징에 포함돼, 텍스트 기반 신호가 신뢰도 판단에 가장 큰 비중을 차지함을 확인했다.
학습‑평가 단계에서는 AdaRank, Coordinate Ascent, RankBoost, SVM‑rank 네 가지 순위 알고리즘을 4‑fold 교차 검증으로 비교하였다. NDCG@25~100 지표에서 AdaRank와 Coordinate Ascent가 최고 성능을 보였으나, 학습 시간과 실시간 재학습 필요성을 고려해 SVM‑rank를 최종 선택하였다. 모든 알고리즘의 테스트 시간은 1초 미만이었으며, SVM‑rank는 학습 시간도 10초 수준으로 가장 효율적이었다.
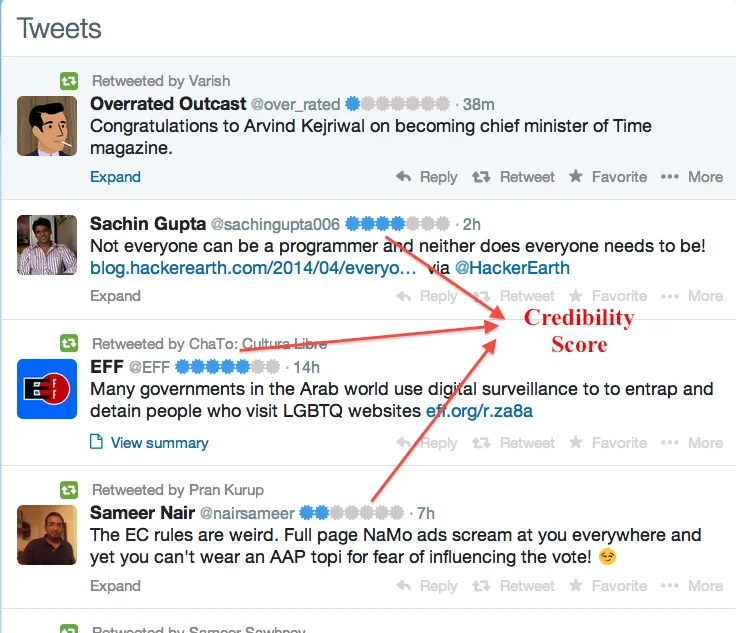
시스템 구현은 브라우저 확장 프로그램, 웹 애플리케이션, REST API 형태로 제공되었으며, 확장 프로그램이 가장 많이 사용되었다. 사용자는 트위터 타임라인을 스크롤할 때 각 트윗 옆에 17 점의 신뢰도 점수가 표시된다. 실험 결과, 80%의 트윗에 대해 6초 이내에 점수가 계산되었고, 사용자 설문에서는 63%가 자동 점수에 전반적으로 동의하거나 작은 차이(12점)만을 보였다.
한계점으로는 라벨링 과정에서 미국 거주자만을 대상으로 했으며, 사건별 특성이 반영된 일반화 가능성에 의문이 남는다. 또한, 텍스트 기반 특징에 편중된 모델은 이미지·동영상·멀티미디어 중심의 트윗에 대한 평가가 어려울 수 있다. 향후 연구에서는 다국어·다문화 라벨링 확대, 멀티모달 특징 통합, 사용자 피드백을 통한 온라인 학습 메커니즘을 도입해 신뢰도 모델을 지속적으로 개선할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기