시간 인식 지식 추출 기반 트위터 마이크로블로그 요약
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
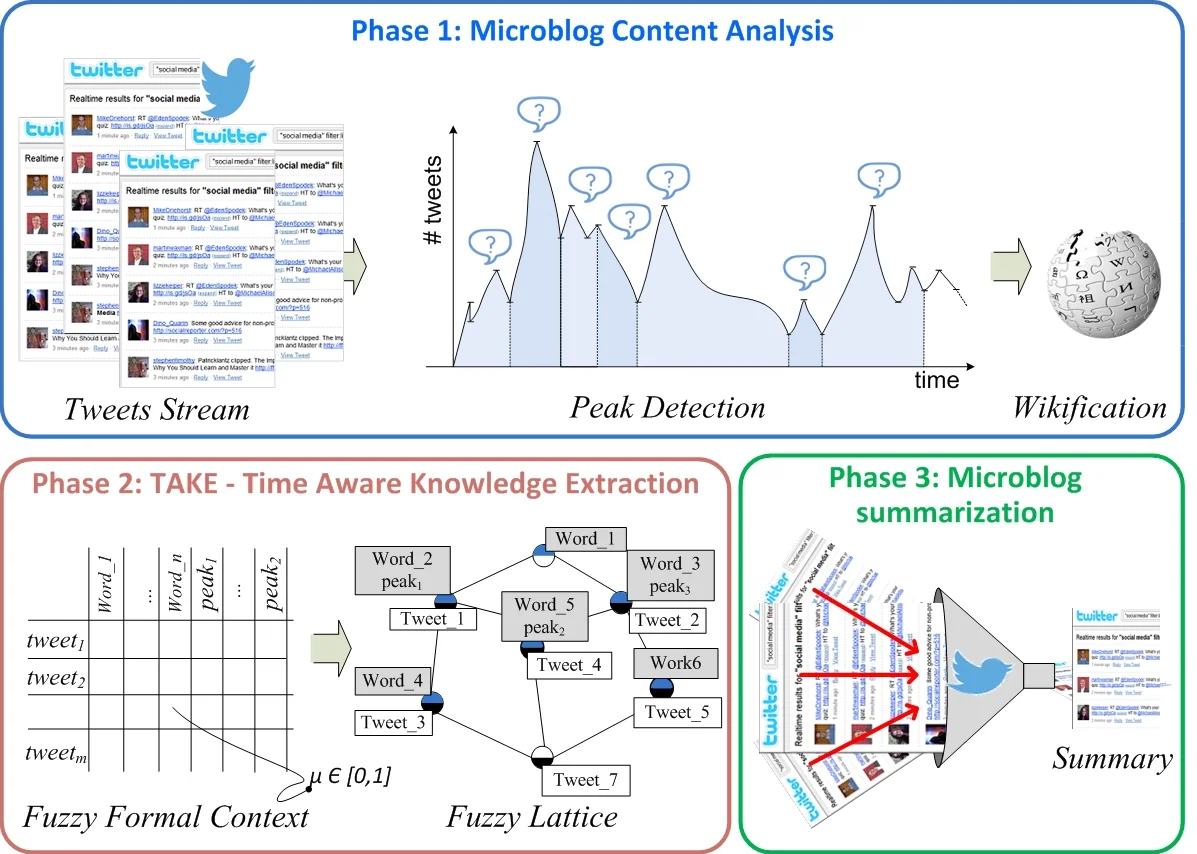
본 논문은 트위터와 같은 마이크로블로그에서 발생하는 방대한 텍스트 흐름을 시간과 의미를 동시에 고려하여 요약하는 새로운 방법론인 TAKE(Time Aware Knowledge Extraction)를 제안한다. Fuzzy Formal Concept Analysis를 시간 차원으로 확장한 ‘시간‑퍼지 래티스’를 구축하고, 이를 기반으로 사용자가 원하는 상세 수준에 맞는 요약을 자동으로 생성한다. 실험 결과, 기존 LDA·DTM 기반 방법보다 신뢰도(Novelty)와 위키피디아 커버리지 측면에서 우수한 성능을 보였다.
상세 분석
TAKE 방법론은 크게 세 단계로 구성된다. 첫 번째 단계인 마이크로블로그 콘텐츠 분석에서는 트윗 스트림을 수집하고, OPAD(Offline Peak‑Finding Algorithm)를 이용해 시간적 피크를 탐지한다. 동시에 각 트윗을 ‘위키피디아화(wikification)’하여 문장을 위키 엔터티 집합으로 변환하고, TF‑IDF 기반의 가중치를 부여한다. 두 번째 단계인 시간‑인식 지식 추출(TAKE)에서는 이러한 시맨틱 벡터와 타임스탬프를 입력으로 받아, 기존 Fuzzy Formal Concept Analysis(FFCA)에 시간 의존 관계를 추가한다. 구체적으로, 객체(트윗)와 속성(위키 엔터티) 사이의 멤버십 값을
댓글 및 학술 토론
Loading comments...
의견 남기기