연애 선택을 위한 알고리즘 헤어질까 또 만날까
초록
본 논문은 전통적인 비밀녀 문제를 확장하여 개인의 심리·사회적 특성을 반영한 연애 선택 알고리즘을 제시한다. 사용자의 성격 검사, 인구통계, 과거 연애 이력 등을 입력으로 삼아 매칭 확률과 효용 함수를 계산하고, 몬테카를로 시뮬레이션을 통해 장기적인 연애 옵션의 가치를 예측한다. 결과는 현재 관계 유지, 독신 유지, 새로운 연애 시도 중 최적 선택을 제시한다.
상세 분석
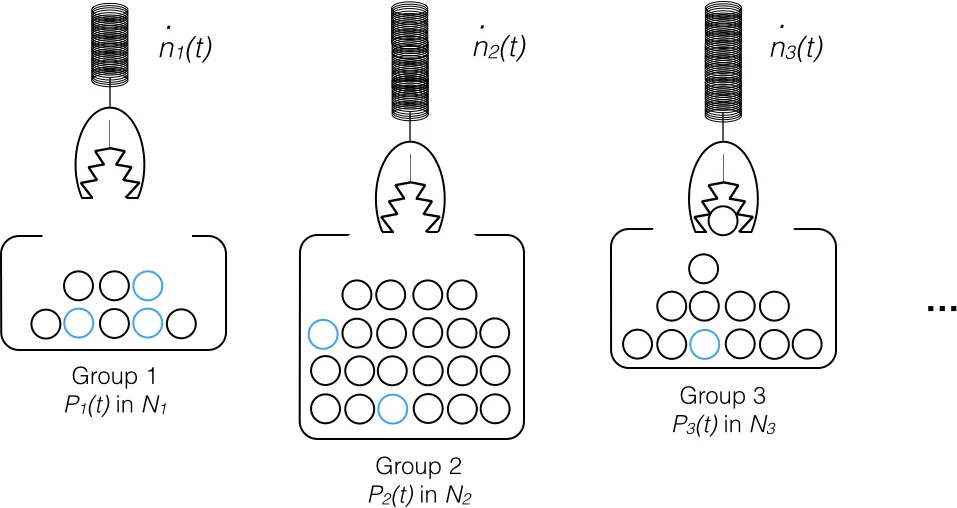
이 논문은 연애 의사결정을 수학적·경제학적 모델에 귀속시키려는 시도로, 기존 비밀녀 문제의 “최적 스톱” 개념을 다차원 심리·사회 변수와 결합한다는 점에서 신선하다. 먼저 사용자와 매칭 대상군을 ‘그룹’과 ‘서브그룹’으로 정의하고, 각 그룹별 인구통계와 성격 특성의 분포를 가정한다. 여기서 핵심은 ‘단일 만남 확률(P_G(t))’과 ‘상호작용 빈도(·n_G(t))’를 추정해 누적 매칭 확률을 구하는데, 이를 위해 저자는 대규모 인구를 가정한 ‘큰 N 한계’와 이항분포 기반의 urn 모델을 적용한다. 이러한 접근은 실제 연애 시장에서의 비정규성(예: 소규모 커뮤니티, 계절적 변동)과는 괴리될 위험이 있다.
효용 함수는 두 종류로 나뉜다. 첫 번째는 두 사람 간의 관계 효용을 D차원 성격 공간에서 평균 거리와 가중치를 이용해 정의한 식(1)이며, 시간에 따라 복리식 감가상각을 적용한다. 두 번째는 ‘싱글 상태’ 효용으로, 사용자의 인생 목표와 현재 감정 상태를 설문 형태로 입력받아 추정한다. 여기서 효용의 단위가 임의적이며, 절대값보다는 상대 비교에 의존한다는 점은 모델의 실용성을 제한한다.
시뮬레이션 단계에서는 사용자의 성격 공간을 주성분 분석(PCA)으로 축소하고, 해당 서브그룹에서 추출된 가상의 매칭 후보들을 몬테카를로 방식으로 생성한다. 이는 ‘가장 이상적인 파트너’를 찾는 것이 아니라 ‘가장 확률이 높은 후보’를 평가함으로써 현실성을 추구한다는 점에서 장점이 있다. 그러나 무작위 생성 과정에서 실제 데이터와의 검증이 부족하고, ‘패널티(벌점)’ 계산식이 구체적으로 제시되지 않아 재현 가능성이 낮다.
논문은 또한 ‘사회학적 모델링’ 파트를 통해 매칭 확률을 시간에 따라 변화시키는 인구 이동·인구 구조 변화를 고려한다. 하지만 인구학적 변수를 어떻게 정량화하고, 어떤 외부 데이터베이스와 연동할지에 대한 구체적 절차가 누락돼 있다. 전체적으로 알고리즘 흐름도와 몇 가지 예시 그래프(품질별, 그룹별 매칭 확률)를 제시하지만, 실험 결과는 한 명의 28세 남성 사례와 51세 남성 사례에 국한돼 있어 일반화에 한계가 있다.
결론적으로, 이 연구는 연애 의사결정을 정량화하려는 야심찬 시도이며, 다차원 심리·사회 변수와 확률론적 시뮬레이션을 결합한 프레임워크를 제시한다. 그러나 가정의 현실성, 데이터 확보 방법, 효용 함수의 주관성, 그리고 검증 절차의 부재가 주요 약점으로 남는다. 향후 실제 사용자 데이터를 통한 베타 테스트와 모델 파라미터의 민감도 분석이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기