적응형 그래프를 이용한 UUID‑MAC 매칭 알고리즘
초록
**
본 논문은 스마트폰 사용 시 수집되는 UUID와 MAC 주소를 동일한 기기로 매핑하기 위해, 일별로 관측되는 두 함수 U(x)와 M(x)의 결과를 이분 그래프로 표현하고, 교차·곱 연산을 통해 점진적으로 매칭을 정제한다. 알고리즘은 병렬 R 구현을 제시하고, 6개월간 6개 공항 데이터를 대상으로 실험하여 매칭 정확도와 연산 시간을 평가한다.
**
상세 분석
**
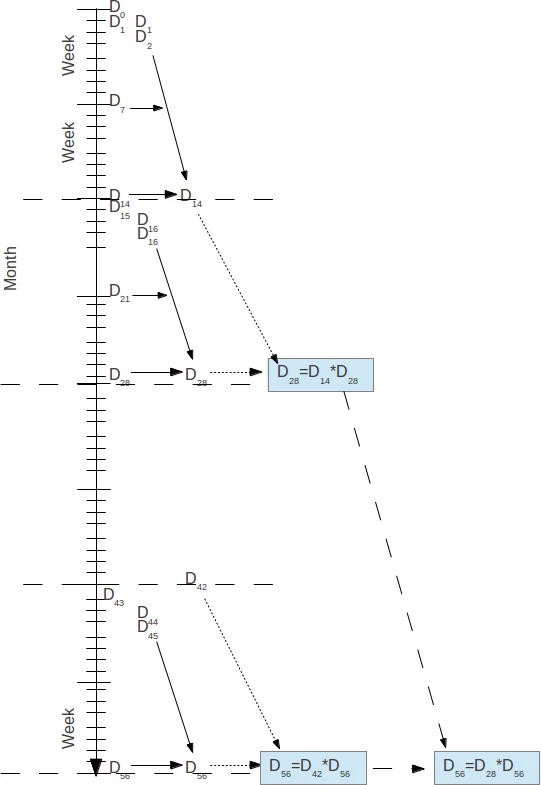
논문은 “두 개의 전단사 함수 U(x)와 M(x) 가 존재한다”는 가정에서 시작한다. 실제 상황에서는 UUID와 MAC 주소가 각각 시간·위치에 따라 관측되지만, 동일한 x (기기)를 직접 알 수 없으므로 관측값만으로 매핑을 추정한다. 이를 위해 저자들은 각 공항 Lᵢ 와 날짜 t 에 대해 S_{Lᵢt} (1 마일 반경 내 사용자 집합)와 M_{Lᵢt} (MAC 주소 집합)을 정의하고, “h S_{Lᵢt} : M_{Lᵢt}” 형태의 완전 이분 그래프를 만든다.
핵심 아이디어는 서로 다른 날·공항에서 얻은 그래프들의 교집합을 이용해 매핑을 점점 좁혀 나가는 것이다. 논문에서는 두 종류의 연산을 도입한다. ‘+’ 연산은 두 매핑을 단순히 합쳐서 더 큰 매핑 집합을 만든다(즉, 아직 교차가 없는 경우); ‘*’ 연산은 주소가 겹치는 경우 사용자와 주소 모두의 교집합을 구해 새로운, 더 작은 매핑을 만든다. 수식 (2.5) ~ (2.8) 은 이러한 연산을 집합론적 관점에서 전개하며, 최종적으로는 모든 일별 그래프 D_{t} 를 차례로 곱해 D_{t_k+1}=D_{t_k+1} * D_{t_k} 와 같은 재귀식으로 결합한다.
알고리즘의 병렬화 전략은 두 단계로 나뉜다. 첫 번째는 시간 구간을 2주 단위로 나누어 각각을 독립적으로 처리하는 ‘embarrassingly parallel’ 단계이며, 두 번째는 이 구간 결과들을 이진 트리 형태로 차례로 곱하면서 각 곱 연산 자체를 다중 코어에서 병렬로 수행한다. 구현은 R 언어와 mclapply 함수를 이용해 P 개의 코어에 작업을 분산한다.
실험에서는 6개 공항, 6개월 데이터(일일 평균 2.5 백만 사용자, 1 만 MAC 주소)를 사용했다. 두 주와 네 주 구간으로 그래프를 구축했을 때, 네 주 그래프가 약 2시간 빠르게 완료되고 매칭 수가 더 많았지만, 두 주 그래프는 매핑이 더 정제되어 중복이 적었다. 이는 교차가 적은 초기 그래프에서 병렬성을 크게 활용할 수 있었기 때문이다.
비판적으로 보면, 논문은 수학적 정의와 연산을 제시하지만 증명이나 복잡도 분석이 부족하다. ‘*’ 연산이 실제로 언제 유의미한 매칭을 생성하는지, 오류(예: 동일 MAC이 여러 UUID에 매핑되는 경우) 처리 방안이 명시되지 않는다. 또한 R 구현은 메모리 사용량이 급격히 증가할 수 있으며, O(N²) 복잡도는 대규모 실시간 시스템에 부적합할 가능성이 있다. 마지막으로, 기존의 bipartite matching, 그래프 정규화, 혹은 probabilistic record linkage 기법과의 차별점이 충분히 논의되지 않아 ‘신규성’에 대한 설득력이 다소 약하다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기