베이지안 관점에서 본 드롭아웃 최적 비율 학습
본 논문은 드롭아웃을 베이지안 모델 평균화의 한 형태로 해석하고, 드롭아웃 비율을 고정값이 아닌 학습 가능한 하이퍼파라미터로 취급한다. 변분 하한(ELBO)을 최대화하는 관점에서 표준 드롭아웃은 사전 지정된 베르누이 분포 q(z) 를 사용한 근사이며, 이를 최적화하면 드롭아웃 비율 λ 를 데이터에 맞게 조정할 수 있다. 제안된 베이지안 드롭아웃 알고리즘은 θ 와 λ 를 교대로 혹은 동시에 확률적 경사 하강법으로 업데이트하며, 실험적으로 비율 최…
저자: Shin-ichi Maeda
본 논문은 드롭아웃을 베이지안 모델 평균화의 한 형태로 재해석하고, 드롭아웃 비율을 데이터에 맞게 최적화하는 새로운 프레임워크를 제시한다.
1. **서론**에서는 대규모 신경망이 과적합을 방지하기 위해 드롭아웃을 사용해 왔으며, 기존 연구들은 이를 변형된 L2 정규화 혹은 입력‑특성 변형으로 설명해 왔다고 언급한다. 그러나 드롭아웃이 실제 베이지안 모델 평균화와 얼마나 일치하는지, 그리고 비율을 어떻게 최적화할 수 있는지는 명확히 제시되지 않았다.
2. **표준 드롭아웃 알고리즘**에서는 3‑계층 신경망을 예시로, 입력 x, 숨김 h, 출력 y 에 대한 마스크 Z^(1), Z^(2) 를 도입하고, 각 마스크 요소를 독립적인 베르누이 변수 z_i 로 정의한다. 학습 단계는 (i) 무작위 샘플 선택, (ii) 비율 p (보통 0.5) 로 마스크 샘플링, (iii) 로그우도에 대한 경사 하강법 업데이트로 구성된다. 예측 단계에서는 마스크의 기대값을 사용해 가중치를 절반으로 스케일링하거나, “fast dropout”을 통해 가우시안 근사를 적용한다.
3. **기존 해석**에서는 드롭아웃을 입력‑특성 손상에 의한 적응형 정규화, 혹은 서브모델 비용 평균으로 보는 관점을 정리한다. 특히, “standout”은 비율을 입력별로 학습하지만, 베이지안 사후와의 연결 고리가 부족하다고 지적한다.
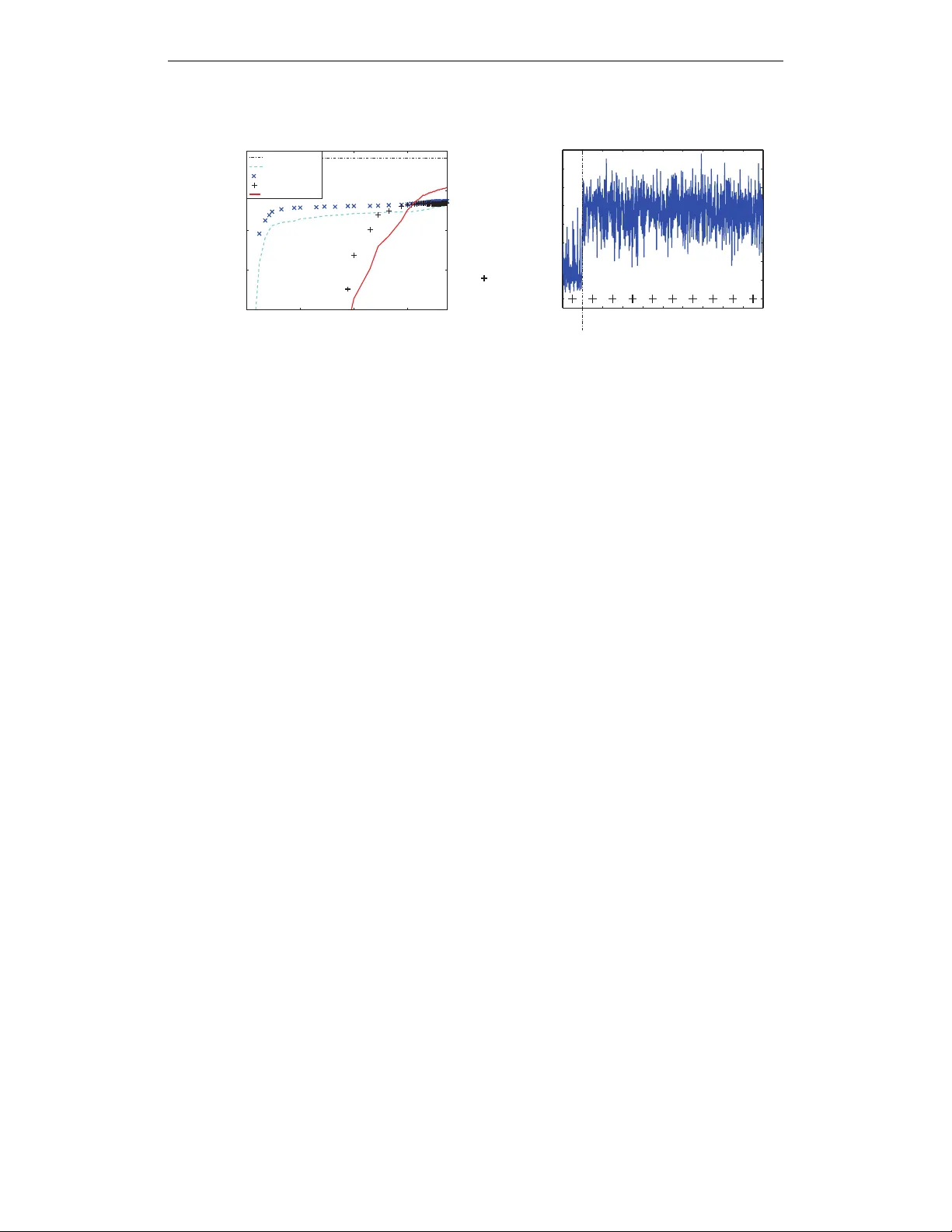
4. **베이지안 해석**에서는 마스크 z 를 파라미터, 가중치 θ 를 하이퍼파라미터로 두고, 주변 로그우도 log p(D|θ)=log∑_z p(D,z|θ) 를 목표로 한다. 변분 하한 F(q,θ)=E_q
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기