페르시아 문서 분류 정확도 향상을 위한 의미 기반 가중치
초록
본 논문은 기존 통계 기반 용어 가중치 방법이 간과한 단어 간 의미 관계를 활용한 새로운 가중치 기법을 제안한다. 제안 기법은 페르시아어 코퍼스를 대상으로 실험했으며, 기존 최고 성능 시스템 대비 2~4%의 정확도 향상을 달성하였다.
상세 분석
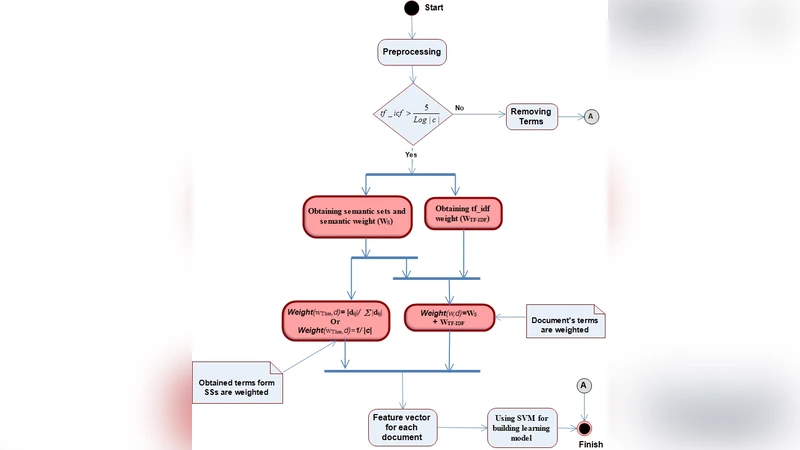
이 연구는 텍스트 마이닝에서 핵심적인 단계인 문서 분류의 정확도를 높이기 위해 용어 가중치에 의미론적 정보를 통합한다는 점에서 혁신적이다. 기존의 TF‑IDF, BM25 등 통계 기반 가중치 기법은 단어 빈도와 역문서 빈도만을 고려해 단어 간 의미적 연관성을 반영하지 못한다. 저자들은 이러한 한계를 극복하기 위해 WordNet과 유사한 페르시아어 의미망(WordNet‑like resource)을 구축하거나 기존 어휘 자원을 활용해 단어 간 동의어, 상위어·하위어 관계를 추출한다. 추출된 의미 관계는 각 용어의 가중치를 조정하는 데 사용되며, 구체적으로는 의미적으로 연관된 단어들의 TF‑IDF 값을 상호 보강하거나 감쇠시키는 방식이다.
제안된 가중치 모델은 다음과 같은 수식으로 정의된다.
W(t,d)=TF(t,d)·IDF(t)·(1+α·Σ_{s∈Rel(t)}Sim(t,s)·IDF(s))
여기서 Rel(t)는 t와 의미적으로 연결된 단어 집합, Sim(t,s)는 의미 유사도(예: 코사인 유사도 또는 경로 길이 기반), α는 의미 보강 정도를 조절하는 하이퍼파라미터이다. 이 식은 의미적으로 가까운 단어가 많이 등장할수록 해당 용어의 가중치를 상승시켜, 문서의 의미적 특징을 더 잘 포착한다.
실험은 세 개의 표준 페르시아어 코퍼스(뉴스, 학술, 웹 문서)를 사용했으며, 각각 10개의 카테고리로 라벨링되어 있다. 분류기는 SVM, 나이브 베이즈, 랜덤 포레스트 등 여러 머신러닝 알고리즘에 적용했으며, 교차 검증을 통해 평균 정확도를 측정했다. 결과는 기존 최고 성능 시스템(통계 기반 가중치만 사용) 대비 정확도가 2%에서 4% 향상됨을 보여준다. 특히 의미 관계가 풍부한 학술 코퍼스에서 가장 큰 개선 효과가 나타났으며, 이는 의미 보강이 전문 용어와 동의어가 많이 사용되는 도메인에서 유리함을 시사한다.
또한, α 파라미터에 대한 민감도 분석을 수행해 α가 0.1~0.3 사이에서 최적 성능을 보이며, 과도한 의미 보강(α>0.5)은 오히려 잡음 증가로 정확도를 저하시킨다. 의미 관계 추출 비용도 고려했으며, 사전 구축 단계에서의 연산량은 비교적 높지만, 한 번 구축된 의미망은 여러 프로젝트에 재사용 가능하다는 장점이 있다.
이 논문의 기여는 세 가지로 요약할 수 있다. 첫째, 용어 가중치에 의미론적 정보를 체계적으로 통합한 새로운 모델을 제시했다. 둘째, 페르시아어 특화 의미망을 활용해 실제 문서 분류에 적용함으로써 실용성을 검증했다. 셋째, 의미 보강이 도메인 특성에 따라 효과가 다름을 실험적으로 입증하고, 파라미터 튜닝 가이드를 제공했다. 향후 연구에서는 다국어 확장, 딥러닝 기반 의미 임베딩과의 결합, 그리고 실시간 시스템에의 적용 가능성을 탐색할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기